



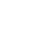



命令行作为日常开发比较常用的的工具,其方便程度被广大程序员所认可,但其实在使用命令行时,可以使用管道操作来对输出结果进行处理。
管道操作就是通过管道符|来将数据流进行传输,然后进行处理,理论上管道命令可以无限叠加。
下面我们就来总结以下一些常用的管道命令(练习文本如下)
VV
vv
aa
bb
bb
bb
cc
cc
11
dd
ee
CC
grep
grep是使用最为频繁的一个管道命令,其作用是对文本进行过滤,例如我们需要从docker 镜像中筛选出 nginx
$ docker images | grep nginx

当然这只是入门级的使用方案,grep还可以通过以下参数来使用更强的功能
| 选项 | 说明 |
|---|---|
| –color | 匹配到的字符显色 never:不考虑颜色 always:always表示在任何情况下都给匹配字段加上颜色标记 auto:auto则只在输出到终端时才加上颜色 |
| -i | 忽略关键字的大小写 |
| -o | 截取匹配的字符串 |
| -v | 对关键字取反 |
| -E | 使用扩展正则 |
| -n | 显示行号 |
| -w | 匹配到的单词 |
不同参数之间可以组合使用,其命令效果如下
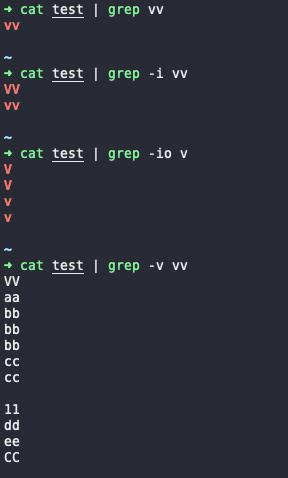
要注意使用正则元字符时需要加引号,否则无效
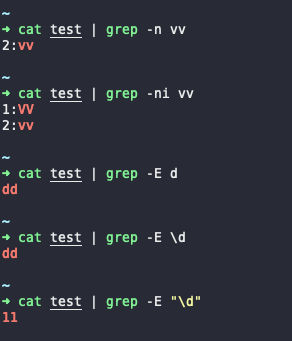
sort
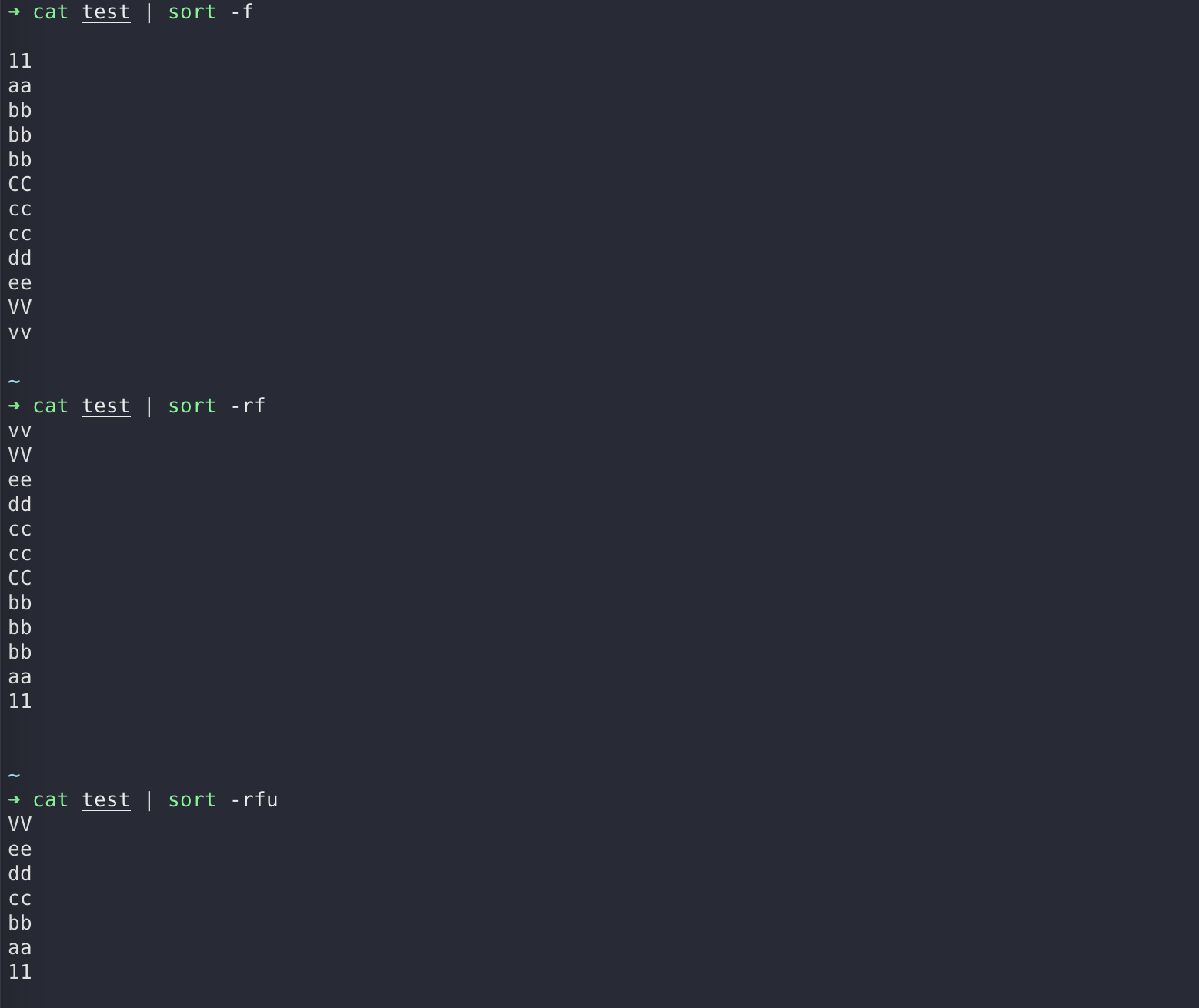
sort从字面意思就能看出是排序的意思,它会对文本内容以行为单位进行排序,默认按照ASCII 码顺序排列。
还是之前的文本,这次我们排序输出
$ cat test | sort
同样他也有参数选项
| 选项 | 说明 |
|---|---|
| -f | 忽略大小写,会将小写字母都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |
| -n | 按照数字进行排序 |
| -r | 反向排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行 |
| -t | 指定字段分隔符,默认使用[Tab]键分隔 |
| -k | 指定排序字段 |
| -o <输出文件> | 将排序后的结果转存至指定文件 |
(uniq这个命令我们后面会说到)
uniq
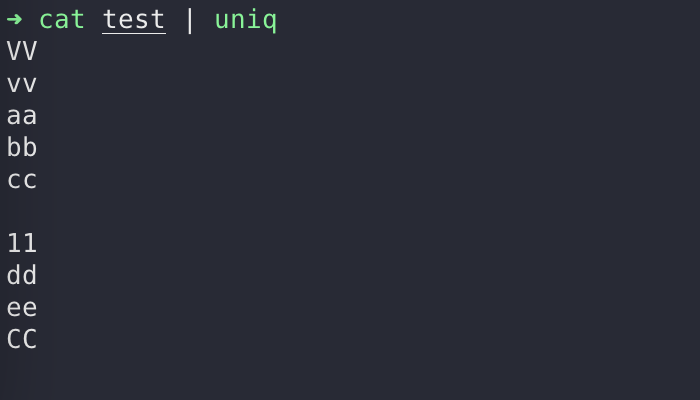
uniq 用于忽略文件中连续重复的行
$ cat test | uniq
| 选项 | 说明 |
|---|---|
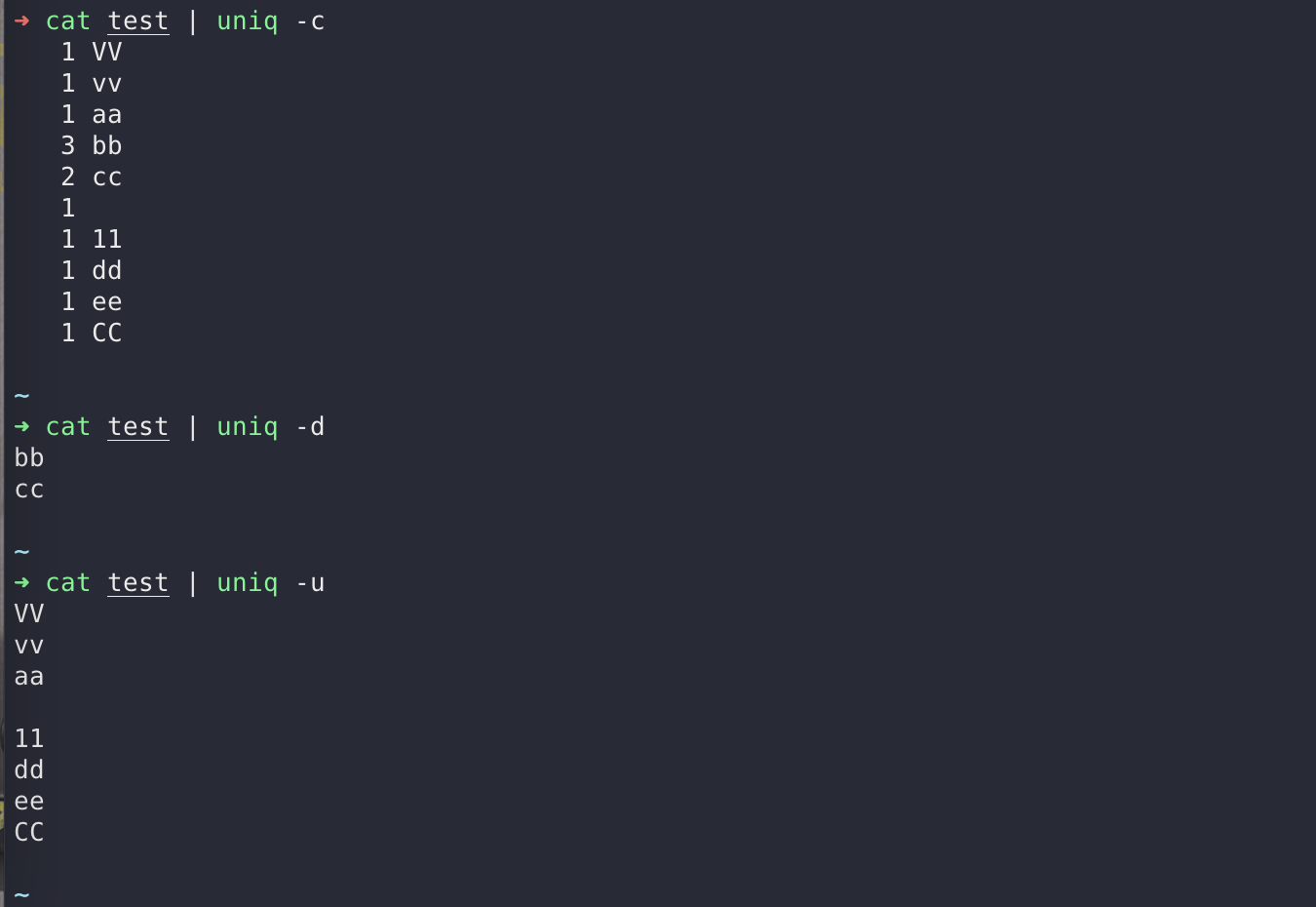
| -c | 进行计数,并删除文件中重复出现的行 |
| -d | 仅显示连续的重复行 |
| -u | 仅显示出现一次的行 |
tr
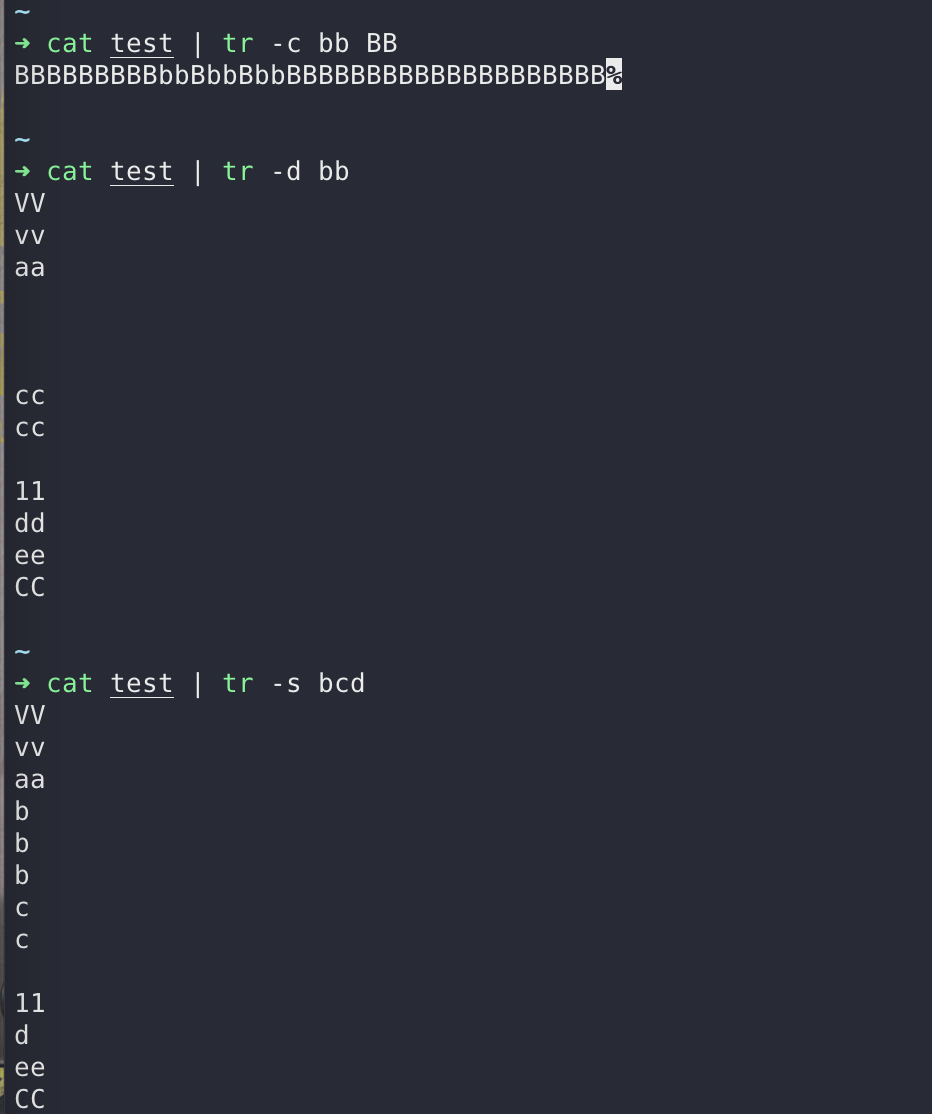
tr 命令常用于对来自标准输入的字符进行替换、压缩和删除
$ cat test | tr 'a-z' 'A-Z'

| 选项 | 说明 |
|---|---|
| -c | 保留字符集1的字符,其他的字符用(包括换行符\n)字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符串;用字符集2 替换 字符集1 |
| -t | 字符集2 替换 字符集1,不加选项同结果 |
cut
cut 命令用于显示行中的指定部分
| 选项 | 说明 |
|---|---|
| -b | 以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志 |
| -c | 以字符为单位进行分割 |
| -d | 自定义分隔符,默认为制表符 |
| -f | 与-d一起使用,指定显示哪个区域 |
| -n | 取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的 范围之内,该字符将被写出;否则,该字符将被排除 |
输入制表符时,先按先 ctrl+v,然后在按下 Tab 键就可以输入 tab 字符
awk
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
语法如下
awk 'BEGIN{ commands } /pattern/ {commands} END{ commands }'
BEGIN{ commands }开始块就是在程序启动的时候执行的代码部分,并且它在整个过程中只执行一次。一般情况下,我们可以在开始块中初始化一些变量。
注意:开始块部分是可选的,你的程序可以没有开始块部分。/pattern/ {commands}pattern 部分匹配该行内容成功后,才会执行commands 的内容。END{ commands }结束块是在程序结束时执行的代码。
注意:结束块部分也是可选的
例如,我们要获取 docker 所有镜像的 ID,我们可以使用 awk 来进行过滤
$ docker images | awk '{print $3}'
如果使用这些 ID 的还需要把首行去掉,那么我们就从第二行开始取
docker images | awk '(NR>1){print $3}'
awk的内建变量如下
| 变量 | 描述(列举常用的,还有很多其他的没怎么常用) |
|---|---|
| $n | $1当前记录的第1个字段的内容。和sed中的$1不同,sed表示第一个参数 |
| $0 | 整行数据的内容 |
| FS | 字段分隔符 (默认是空格) |
| OFS | 输出字段的分隔符(默认是空格) |
| RS | 行分隔符(默认以\n作为一行的结尾),单行分割成多行用到 |
| NR | 行号,从1开始,多文件时候也是连续接着计数 |
| FNR | 各文件分别计数的行号,多文件的时候会和NR不同,它会重新计数 |
| NF | 一行中字段数量,最后一个字段内容可以用$NF取出 |
| ARGC | 命令行参数的数目 |
| ARGV | 包含命令行参数的数组,第一个参数是命令awk |
awk 的参数选项如下
| 选项 | 含义 |
|---|---|
| -F | -F ','或者 -F '正则表达式' -F选项来改变字段分隔符 |
| -v | -va=1赋值一个用户定义变量a的值为1 |
| -f | -f scripfile,从脚本文件中读取awk命令 |
awk循环和数组
现在我们有这么一个文件
user1 10 20 30 44 55
user2 99 10 45 66 42
user3 11 31 45 64 19
我们要求出每个用户的平均值,我们可以使用 awk 脚本来执行
$ cat test | awk '{sum=0;for(c=2;c<NF;c++) sum+=$c; print sum/(NF-1)}'

这里用到的都是我们上面表格里面的内建变量,如果在优化一点可以在输出结果上添加 username
$ cat test | awk '{sum=0;for(c=2;c<NF;c++) sum+=$c;average[$1]=sum/(NF-1)} END{for(user in average) print user,average[user]}'




