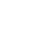



音视频概念铺垫
视频
视频的播放原理:多张图片在短时间内播放,人眼就会认为是一段连贯的动作,以前的胶片电影,还有小时候玩过的快速翻页就能看动画的小书……
视频的一些属性
- 分辨率:屏幕是由一个个像素点组成的,我们常见的1080p,是指屏幕竖直方向有1080个像素,共有1920列,一共207万像素。2K,2560x1440,共369万像素。
- 比特率:码率,也叫比特率,帧率是1S播放多少帧,类比一下,比特率就是1s的视频有多少bit。这个参数决定了视频是否清晰。
常见视频格式
常见的视频格式主要有:.mov、.avi、.mpg、.vob、.mkv、.rm、.rmvb等,之所以会有这么多种视频格式,是因为他们使用了不同的方式来封装视频,所以他们具有各自的特色。
他们的主要特点如下
| 视频文件格式 | 视频封装格式 | 释义 | 发行公司 |
|---|---|---|---|
| .avi | AVI(Audio Video Interleave) | 图像质量好,但体积过于庞大,压缩标准不统一,存在高低版本兼容问题。 | MicroSoft.1992 |
| .wmv | WMV(Windows Media Video) | 可边下载边播放,很适合网上播放和传输 | MicroSoft.2003 |
| .mpg .mpeg .mpe .dat .vob .asf .3gp .mp4 | MPEG(Moving Picture Experts Group) | 有三个压缩标准,分别是 MPEG-1、MPEG-2、和 MPEG-4,它为了播放流式媒体的高质量视频而专门设计的,以求使用最少的数据获得最佳的图像质量。 | 运动图像专家组.1998 |
| .mkv | Matroska | 一种新的视频封装格式,它可将多种不同编码的视频及 16 条以上不同格式的音频和不同语言的字幕流封装到一个 Matroska Media 文件当中。 | Matroska.2002 |
| .rm、.rmvb | Real Video | 用户可以使用 RealPlayer 根据不同的网络传输速率制定出不同的压缩比率,从而实现在低速率的网络上进行影像数据实时传送和播放。 | Real Networks |
| .mov | QuickTime File Format | 默认的播放器是苹果的 QuickTime。这种封装格式具有较高的压缩比率和较完美的视频清晰度等特点,并可以保存 alpha 通道。 | Apple.1998 |
| .flv | Flash Video | 由 Adobe Flash 延伸出来的一种网络视频封装格式。这种格式被很多视频网站所采用。最常见的是用来搭配rmtp | Adobe.2005 |
「视频封装格式」= 视频 + 音频 +「视频编解码方式」 等信息的容器。
常见的解码方式
.H26x系列 由国际电传视讯联盟远程通信标准化组织(ITU-T)主导,包括 H.261、H.262、H.263、H.264、H.265。
- .H261 用于老的视频会议或视频电话系统,之后的所有标准都基于它设计的。
- .H262 等同于 MPEG-2 第二部分,使用在 DVD、SVCD 和大多数数字视频广播系统和有线分布系统中。
- .H263 主要用于视频会议、视频电话和网络视频相关产品。比它之前的视频编码标准在性能上有了较大的提升。尤其是在低码率端,它可以在保证一定质量的前提下大大的节约码率。
- .H264 等同于 MPEG-4 第十部分,也被称为高级视频编码(Advanced Video Coding,简称 AVC),是一种视频压缩标准,一种被广泛使用的高精度视频的录制、压缩和发布格式。该标准引入了一系列新的能够大大提高压缩性能的技术,并能够同时在高码率端和低码率端大大超越以前的诸标准。
- .H265 高效率视频编码(High Efficiency Video Coding,简称 HEVC)是一种视频压缩标准,是 H.264 的继任者。HEVC 被认为不仅提升图像质量,同时也能达到 H.264 两倍的压缩率(等同于同样画面质量下比特率减少了 50%),可支持 4K 分辨率甚至到超高画质电视,最高分辨率可达到 8192×4320(8K 分辨率),这是目前发展的趋势。
MPEG系列 由国际标准组织机构(ISO)下属的运动图象专家组(MPEG)开发。
- MPEG-1 第二部分,主要使用在 VCD 上,有些在线视频也使用这种格式。该编解码器的质量大致上和原有的 VHS 录像带相当。
- MPEG-2 第二部分,等同于 H.262,使用在 DVD、SVCD 和大多数数字视频广播系统和有线分布系统中。
- MPEG-4 第二部分,可以使用在网络传输、广播和媒体存储上。比起 MPEG-2 第二部分和第一版的 H.263,它的压缩性能有所提高。
- MPEG-4 第十部分,等同于 H.264,是这两个编码组织合作诞生的标准。
音频
声音信号转为数字信号
- 采样:把时间连续的模拟信号在时间轴上离散化,在某些特定的时刻获取声音信号幅值,其时间间隔称为采样周期,倒数为采用频率;
- 量化:把采样后连续取值的每个样本转换为离散值表示,即对样本进行A/D转换(模数转换);量化后的样本用二进制数来表示,二进制位数即为量化精度(如用1个字节表示,样本的取值范围是0-255,则精度是1/256);
- 编码:以上处理后得到的数字形式的信息,为了便于存储、处理和传输,进行压缩处理。
数字信号的主要参数
- 采样频率:表示每秒内采样的次数,常用为44.1KHz、22.05KHz、11.05KHz;
- 量化位数:度量声音波形幅度的精度,一般为8位、12位或16位;
- 声道数目:N声道一次产生N组声音波形数据(基于不同的位置)。
如果一段10s的音频,其采用频率是44.KHz,量化精度是16位,采用双声道,则其数据量为44.1Kx16bx2x10s。
常见音频格式
| 音频格式 | 特点 | 音质\压缩 | 发行公司 |
|---|---|---|---|
| MP3 | 最常见的音频封装格式,能够在音质丢失很小的情况下把文件压缩到更小的程度,每分钟音频大约在1M左右;缺点是没有高频部分 | 较好\高 | Fraunhofer-Gesellschaft.1991 |
| WMA | 具有比MP3更好的压缩率,大小大约是MP3的一半,可以防止拷贝和限制播放次数,防盗版方面具有独特的优势 | 一般\高 | MicroSoft |
| WAV | 最早的数字音频格式,支持多种音频位数、采样频率和声道,采用44.1kHz的采样频率,音质与CD相差无几,需要存储空间大 | 好\低 | MicroSoft.1991 |
| AAC | 是MPEG-2规范的一部分,压缩能力远超MP3,AAC可以在比MP3文件缩小30%的前提下提供更好的音质 | 较好\极高 | Fraunhofer IIS-A、杜比和AT&T共同开发 |
| MP3Pro | MP3格式的升级版本,在保持相同的音质下同样可以把声音文件的文件量压缩到原有MP3格式的一半大小 | 较好\极高 | 瑞典Coding科技公司 |
| VQF | 相同情况下压缩后VQF的文件体积比MP3小30%~50%,但VQF未公开技术标准,至今未能流行开来。 | 较好\极高 | YAMAHA和NTT共同开发 |
| FLAC | 无损音频压缩编码,不会破坏原有的音质 | 极好\一般 | MicroSoft.1991 |
| APE | 流行的数字音乐文件格式之一,APE是一种无损压缩音频技术。与FLAC相比,体积较小。编码速度偏慢 | 极好\高 | Matthew T. Ashland |
| MID | 数字化乐器接口,常见的MIDI键盘等编曲乐器都靠这个格式来传输 | YAMAHA、ROLAND、KAWAI等 | |
| OGG | 新的音频压缩格式,支持多声道,完全免费,目前最好的有损格式之一 | 一般/ |
小知识:20kHz是人耳能够听到的声音信号的带宽,根据采样定理,要通过数字信号(如CD,mp3,wav等音频文件)恢复出原始的声音信号,采样速率至少为带宽的2倍,即40kHz。而使用44kHz比40kHz多了10%,是因为这样能够简化耳机中的滤波器设计,且使得滤波能够滤除更多的噪音,从而提高耳机的音质,让你基本听不到杂音。
音视频通讯原理
NAT
网络地址转换协议。由于IPv4地址过于稀缺,不足以分配给每一台设备一个IP,本就不多的IP地址被列强占据大部分,再扣去保留地址,剩下的寥寥无几。不过好在有NAT,可以支撑我们能在因特网中冲浪🏄🏻。
所有同一个局域网内部的设备共用一个公网IP,在内部通过映射来区分不同设备的网络请求。
从表面上来看,NAT可以分为三大类型:静态NAT(基本)、动态地址NAT(基本)、地址端口转换NAPT(变种)
- 静态NAT:将内部私网地址与公网地址进行一对一的转换,每个内部地址的转换都是确定的
- 动态NAT:将内部私网地址与公网地址进行一对一的转换,但是动态地址转换是从合法的地址池中动态选择一个未使用的地址来对内部私有地址进行转换。和静态NAT的明显区别是
动态NAT有多个公网IP - 地址端口转换NAPT:也是一种动态转换,而且内部多个地址被转换成同一个合法公网地址,使用不同的端口号来区分不同的设备和进程。
基本型NAT可以直接连接,变种NAT是无法直连的。
在NAPT中,又可以将NAT分为四类:全锥型NAT、地址受限锥型NAT、端口受限锥型NAT、对称NAT(基本的NAT已经非常少见了,NAPT才是我们常说的NAT,这里的NAT其实都是NAPT)
全锥型NAT:所有从同一个内网的(IP,端口)发送出来的请求都会被映射到同一个外网(IP,端口),且任何一个外网主机都可以通过访问映射后的公网地址,实现访问位于内网的主机设备功能。外网主机可以主动连接内网主机。

地址受限锥型NAT:所有从同一个内网的(IP,端口)发送出来的请求都会被映射到通过一个外网(IP,端口),但与全锥型不同点在于:生成的映射表项与目的IP有关,只有符合要求的目的IP(要访问的公网服务器IP)才可以通讯。此NAT还有个特点:不能主动连接内网中的主机地址,连接必须由内网地址发起。比起全锥型NAT多了地址限制。
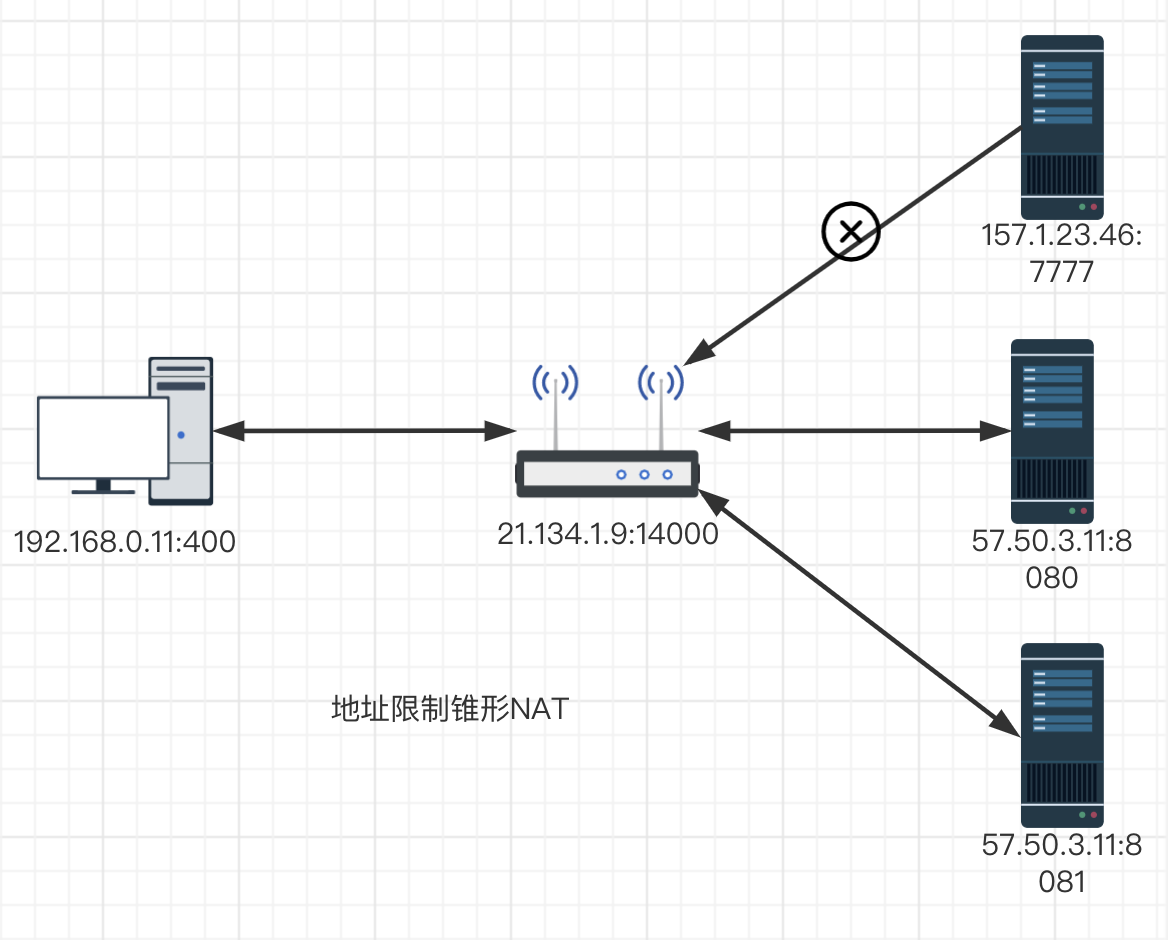
端口受限锥型NAT:所有从同一个内网的(IP,端口)发送出来的请求都会被映射到通过一个外网(IP,端口),但是在地址受限锥型NAT基础上增加了端口的限制。
地址受限锥型NAT时,只有内网主机主动连接的公网主机才可与之进行通讯,而不用担心端口号是否与请求的端口相同。端口受限锥型NAT除了IP限制外,增加了端口限制。
对称NAT:所有从同一个内网(IP,端口)发送到同一个目的IP和端口的请求都会被映射到同一个IP和端口。(SIP,Sport, DIP, Dport)只要有一个发生变化都会使用不同的映射条目,即此NAT映射与报文四元组绑定。(较其他类型而言安全性较高,多用于3G、4G、公共WIFI等)
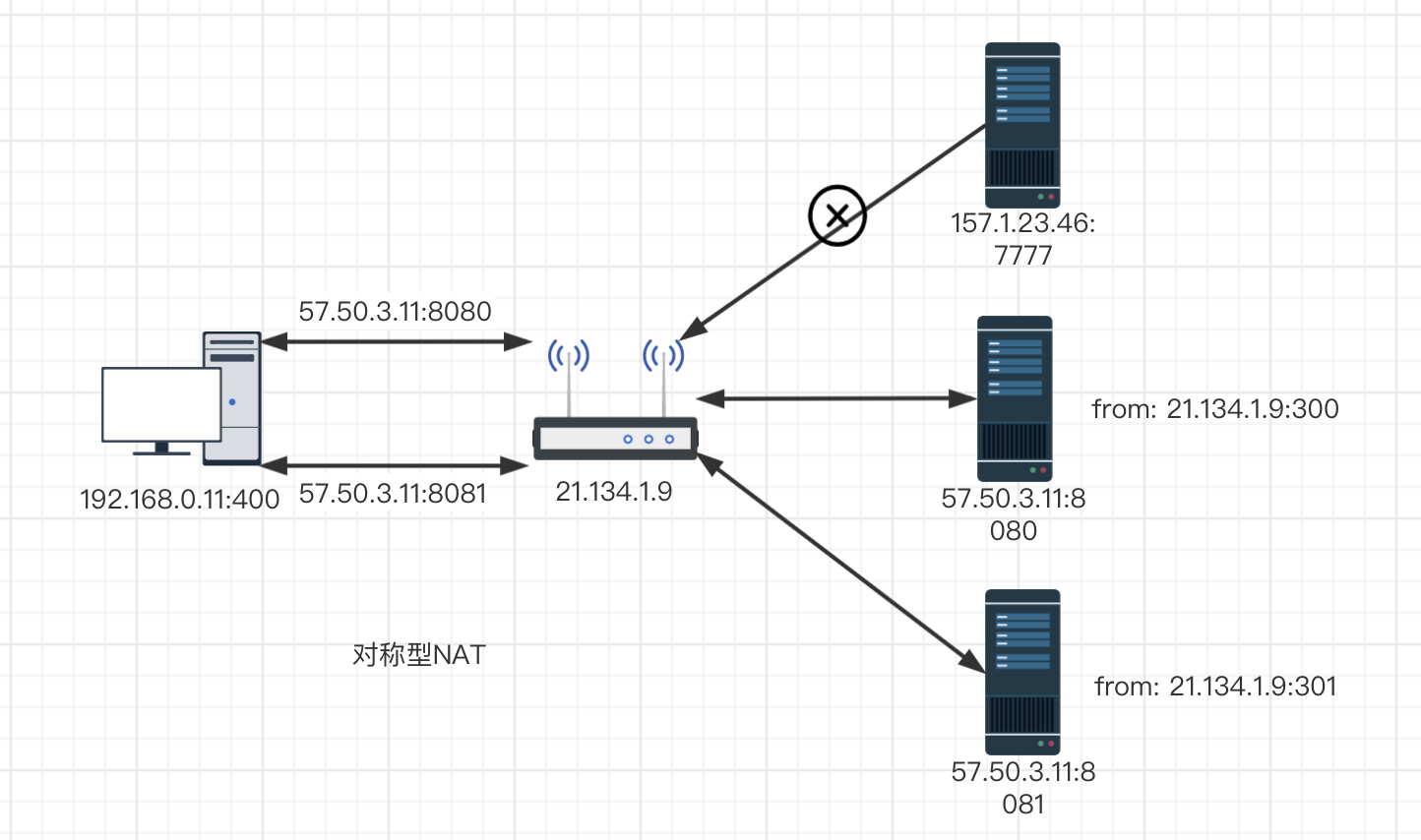
由于NAT的存在,我们可以在网络世界中遨游,也正是由于NAT的存在,我们无法直接在两台设备之间进行数据通讯,所以就有了——“打洞”。
P2P打洞
所谓的打洞就是STUN,Session Traversal Utilities for NAT,NAT会话穿越应用程序。STUN是一种网络协议,它允许位于NAT(或多重NAT)后的客户端找出自己的公网地址,查出自己位于哪种类型的NAT之后以及NAT为某一个本地端口所绑定的Internet端端口。这些信息被用来在两个同时处于NAT路由器之后的主机之间建立UDP通信。
当然并不是所有的NAT后面的设备都可以进行打洞,先来看表,至于原因,再了解打洞原理之后就明白了。
| 本端(NAT类型) | 对端(NAT类型) | 是否可以打洞 |
|---|---|---|
| 全锥型 | 全锥型 | ✅ |
| 全锥型 | 地址限制锥型 | ✅ |
| 全锥型 | 端口限制锥型 | ✅ |
| 全锥型 | 对称型 | ✅ |
| 地址限制锥型 | 地址限制锥型 | ✅ |
| 地址限制锥型 | 端口限制锥型 | ✅ |
| 地址限制锥型 | 对称型 | ✅ |
| 端口限制锥型 | 端口限制锥型 | ✅ |
| 端口限制锥型 | 对称型 | ❌ |
| 对称型 | 对称型 | ❌ |
关于UDP打洞的原理,先来看图,后面的许多内容都会基于这张图进行延伸。
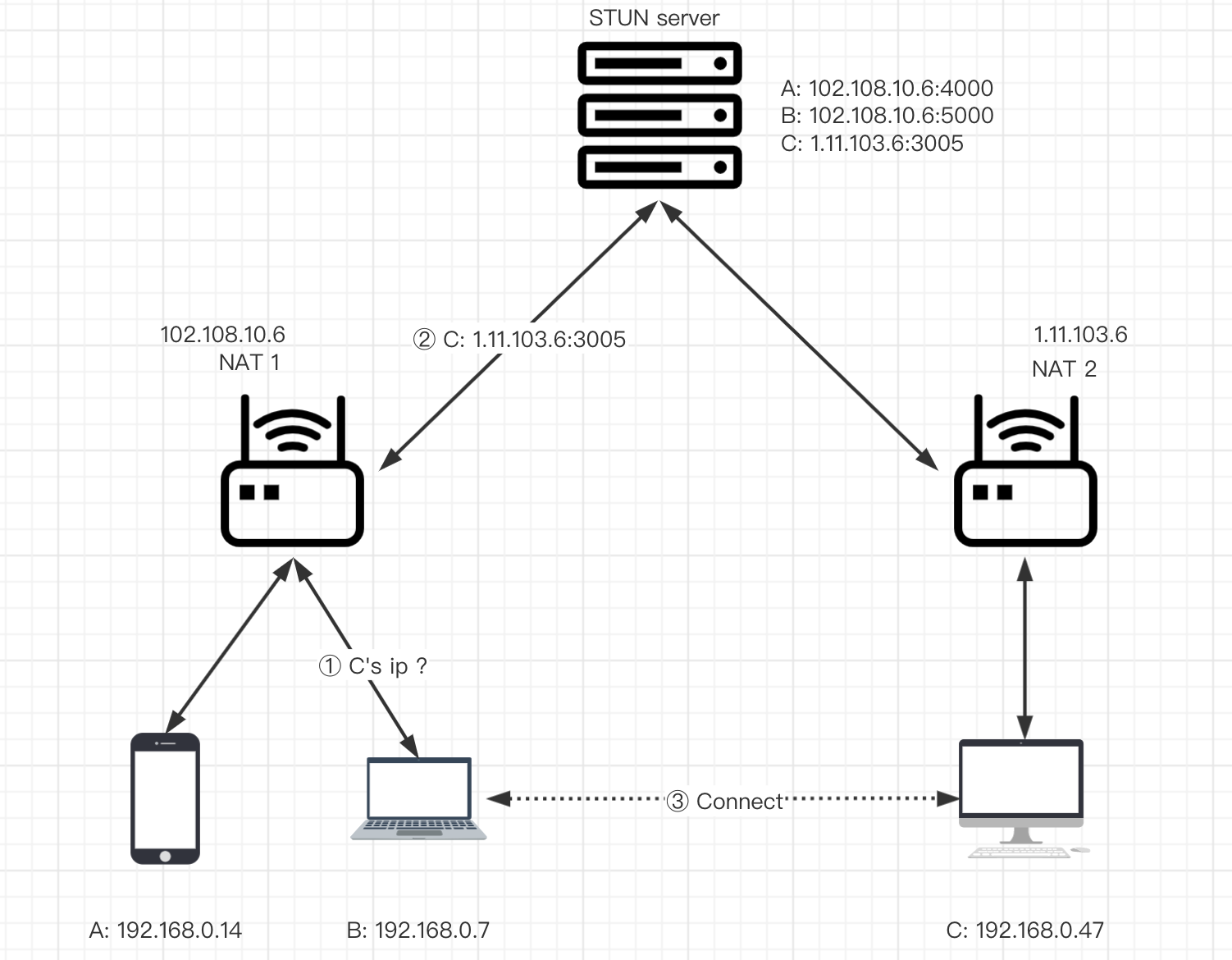
B机器想要和C机器之间进行数据交换,起大致过程如下
- B、C机器都要在STUN服务器上进行注册,将各自的公网地址保存在STUN服务器;
- B、C机器分别从STUN获取对端的ip+端口;
- B机器向C的地址发送数据包,此时NAT2并不知道这条报文该发到局域网中的哪一台设备,所以丢弃此条数据,虽然这条数据并没有发送成功,但是,在NAT1中已经打开了B到C的口子,接受到来自C的数据都转发到B;
- C机器重复步骤3;
- 此时,B、C两台机器都打通了与对端都打通了与对端进行通讯的口子,这时一条穿越NAT的隧道已经打通,两端可以进行数据通讯。
在了解了打洞的过程之后,再来看一下不能打洞的情况(为了看起来方便省去了NAT层,其实是有NAT的),A所在的是端口限制锥型NAT,B所在的是对称型NAT。
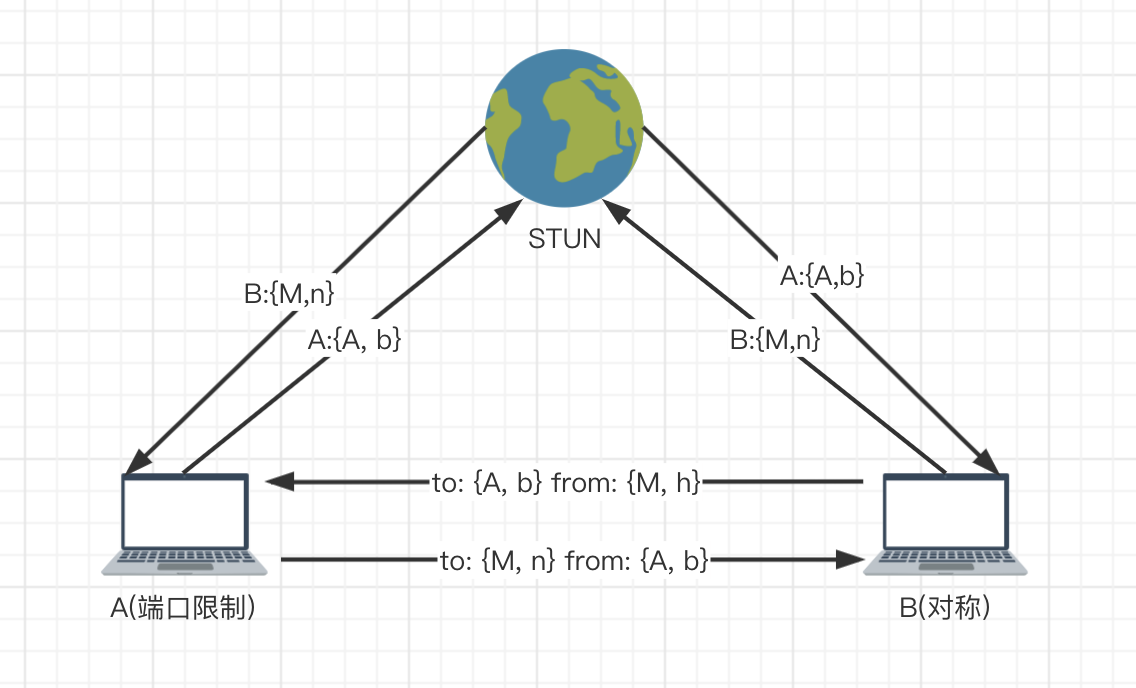
- 首先双方向STUN注册自己,然后获取对端的地址;
- 分别向对端发送数据报,之前的NAT分类中说到了对称NAT的特点,所以B向A设备发送数据时的地址和注册在STUN中的地址是不一致的,此时B所在的NAT允许{A, b}和{M, h}之间进行数据交互;A设备向B在STUN注册的地址发送数据,此时A所在的NAT允许{A, b}和{M, n}之间进行数据交互;
- 所以现在的情况是,A、B所在NAT均因接收到的消息与白名单中端口不匹配而被丢弃
所以这种情况下是无法进行打洞的,同样的道理,双方均为对称型NAT时也是无法进行通讯的。这两种情况无法使用P2P直接连接,但是可以通过一台中继服务器(TURN)进行数据转发,这就要求TURN具有较高的处理能力和网络带宽。
WebRTC连接过程
经过前面几部分的铺垫,你应该对P2P音视频互动的过程有了一个大概的了解,有可能你会觉得过程比较繁琐,甚至涉及到了网络底层。但是,不要担心,WebRTC已经帮我们做了很多的事情,让我们在音视频开发时变得轻而易举。那么WebRTC到底是什么呢?
WebRTC (Web Real-Time Communications) 是一项实时通讯技术,它允许网络应用或者站点,在不借助中间媒介的情况下,建立浏览器之间点对点(Peer-to-Peer)的连接,实现视频流和(或)音频流或者其他任意数据的传输。WebRTC包含的这些标准使用户在无需安装任何插件或者第三方的软件的情况下,创建点对点(Peer-to-Peer)的数据分享和电话会议成为可能。
WebRTC并不是Google原来自己的技术。在2010年,Google以大约6820万美元收购了VoIP软件开发商Global IP Solutions公司,并因此获得了该公司拥有的WebRTC技术。如今,互联网的音频、视频通信服务技术一般都是私有技术,如Skype, 需要通过安装插件或者桌面客户端来实现通信功能。Google希望Web开发人员能够直接在浏览器中创建视频或语音聊天应用,Global IP Solutions公司之前已经针对Android、Windows Mobile、iPhone制作了基于WebRTC的移动客户端。Google此次将WebRTC开源出来,就是希望浏览器厂商能够将该技术直接内嵌到浏 览器中,从而方便Web开发人员。
概念补充
除了之前提到的概念之外,再来补充几个相关的概念
交互式连接设施
交互式连接设施(Interactive Connectivity Establishment, ICE):允许你的浏览器和对端浏览器建立连接的协议框架。在实际的网络当中,有很多原因能导致简单的从A端到B端直连不能如愿完成。这需要绕过阻止建立连接的防火墙,给你的设备分配一个唯一可见的地址(通常情况下我们的大部分设备没有一个固定的公网地址),如果路由器不允许主机直连,还得通过一台服务器转发数据。你可能已经发现这个ICE就是我们之前STUN、TURN等连接方式的汇总,正式由于ICE框架,大大简化了我们的开发工作,ICE会按照优先级自动选择连接方式;
信令服务器
信令服务器(signal server):交换Peer之间的可通讯地址,通过STUN获取到自己的通讯地址之后,注册在信令服务器上就可以交换设备之间的通讯地址,从而完成P2P连接;
会话描述协议
会话描述协议(Session Description Protocol, SDP):描述多媒体连接内容的协议,例如分辨率,格式,编码,加密算法等。在开始P2P连接之前需要先协商双方共同支持的会话协议。当用户对另一个用户启动WebRTC调用时,将创建一个称为提议(offer)的特定描述。 该描述包括有关呼叫者建议的呼叫配置的所有信息。 接收者然后用应答(answer)进行响应,这是他们对呼叫结束的描述。 以这种方式,两个设备彼此共享以便交换媒体数据所需的信息;一个SDP描述的内容是这样的(“=”两边不能有空格)
v=0
o=- 212360934117607227 2 IN IP4 127.0.0.1
s=-
t=0 0
m=audio 9 UDP/TLS/RTP/SAVPF 111 103 104 9 0 8 106 105 13 110 112 113 126
a=rtpmap:111 opus/48000/2
......
m=video 9 UDP/TLS/RTP/SAVPF 96 97 98 99 100 101 102 121 127 120 125 107 108 109 35 36 124 119 123 118 114 115 116
a=rtpmap:96 VP8/90000
......
一个SDP描述由一个会话和多个媒体描述组成,会话描述是v=开始到第一段媒体描述(1-4行),媒体描述是从m=到下一个媒体描述之前(5-6行——音频、8-9行——视频)。
会话级描述
会话描述字段比较多,最主要的有4个字段
v=:UDP的版本号,不包含次版本
o=:是一个会话发起者的描述
o=
<username>:用户名,当不关心用户名时,可以用 “-” 代替 ;<session id>:数字串,在整个会话中,必须是唯一的,建议使用 NTP 时间戳;<version>:版本号,每次会话数据修改后,该版本值会递增;<network type>:网络类型,一般为“IN”,表示“internet”;<address type>:地址类型,一般为 IP4;<address>:IP 地址
Session Name:表示一个会话
t=:开始时间和结束时间的描述,
t=<start time> <stop time>,两个事件均为0时表示持久会话
WebRTC中的SDP
WebRTC下对SDP做了一些修改,在原有的基础上增加了一些其他描述
// 音频使用9端口收发;
// UDP / TLS / RTP / SAVPF 表示使用 dtls / srtp 协议对数据加密传输;
m = audio 9 UDP / TLS / RTP / SAVPF 111 103 104 9 0 8 106 105 13 110 112 113 126
// 网络描述, webRTC不使用
c = IN IP4 0.0.0.0
// 设置rtcp地址和端口, webRTC不使用
a = rtcp: 9 IN IP4 0.0.0.0
// 安全验证信息
a=ice-ufrag:duP8
a=ice-pwd:/7pIrSvgESATKPZUVzHhLQ0E
a=ice-options:trickle
// 音频流媒体描述
a=rtpmap:111 opus/48000/2
a=rtcp-fb:111 transport-cc
a=fmtp:111 minptime=10;useinbandfec=1
a=rtpmap:103 ISAC/16000
a=rtpmap:104 ISAC/32000
a=rtpmap:9 G722/8000
a=rtpmap:0 PCMU/8000
a=rtpmap:8 PCMA/8000
a=rtpmap:106 CN/32000
a=rtpmap:105 CN/16000
a=rtpmap:13 CN/8000
a=rtpmap:110 telephone-event/48000
a=rtpmap:112 telephone-event/32000
a=rtpmap:113 telephone-event/16000
a=rtpmap:126 telephone-event/8000
媒体描述
- m=:表示一个会话,
m=<media> <port> <transport> <fmt list><media>:媒体类型,比如 audio/video 等;<port>:端口;<transport>:传输协议,有两种——RTP/AVP 和 UDP;<fmt list>:媒体格式,即数据负载类型 (Payload Type) 列表。
- a=*:
a=<type>或者a=<type>:<value>,type有两种类型rtpmap和fmap
现在我们来完善一下之前网关那里的示意图,添加上这里的几个概念
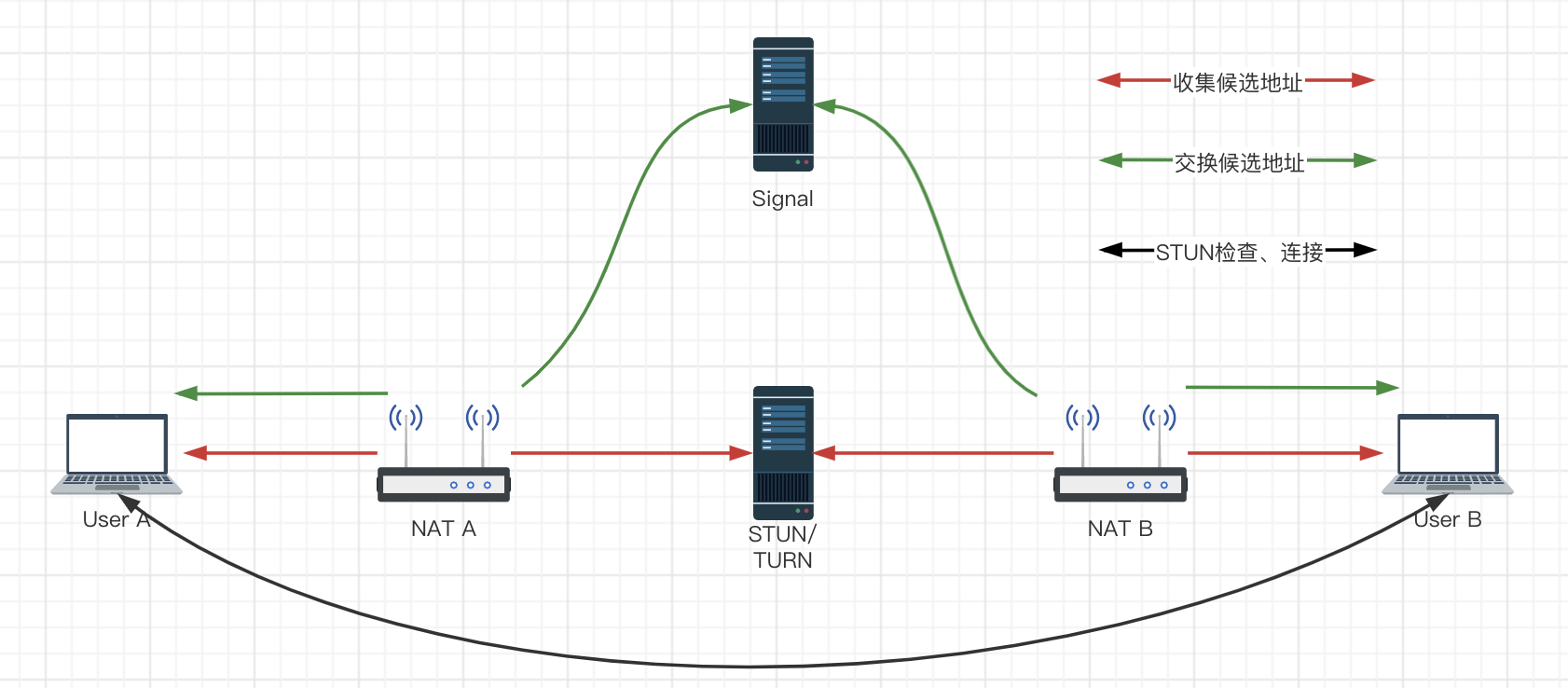
收集候选地址
所谓的收集候选地址,就是通过之前说到的STUN服务器来获取自身的可通讯地址。
| 类型 | 别名 | 如何传给对端 | 用法 |
|---|---|---|---|
| 主机候选项 | host | 信令服务器 | 从网卡中获取的本地传输地址,如果此地址位于NAT之后,则为内网地址 |
| 服务器反射候选项 | srflx | 信令服务器 | 从发送给Stun服务器的Binding检查中获取的传输地址。如果此地址位于NAT之后,则为最外层NAT的公网地址 |
| 对端反射候选项 | prflx | Stun Binding请求 | 从对端发送的Stun Binding请求获取的传输地址。这是一种在连接检查期间新发生的候选项 |
| 中继候选项 | relay | 信令服务器 | 媒体中继服务器的传输地址。通过使用TURN Allocate请求获取 |
交换候选地址
A通过信令服务器把第一步收集到的候选地址发送给B,B也将收集到的候选地址发送给A,A在接收到B的所有候选地址之后会将自身候选地址与对端候选地址进行全排列,存储到状态表中。比如A此时的host是192.168.0.100:60000、srflx是11.102.30.3:30110,B的host是192.168.0.15:10001、srflx是1.10.108.25:30110,状态表如下
| 本地网卡地址 | 对端地址 | 状态 |
|---|---|---|
| 192.168.1.105:60001 | 192.168.0.204:40001 | 未进行过Stun检查 |
| 172.16.40.6:60003 | 192.168.0.204:40001 | 未进行过Stun检查 |
| 192.168.1.105:60001 | 11.92.14.8:50002 | 未进行过Stun检查 |
| 172.16.40.6:60003 | 11.92.14.8:50002 | 未进行过Stun检查 |
| 192.168.1.105:60001 | 192.168.0.181:40003 | 未进行过Stun检查 |
| 172.16.40.6:60003 | 192.168.0.181:40003 | 未进行过Stun检查 |
此时所有的记录状态都是未进行STUN检查,下一步就会进行每条记录的STUN检查。
STUN检查
STUN检查的过程我们之前有过介绍,如有遗忘可以再温习一下,传送门
连接,启动媒体
STUN检查结束之后开始准备连接,此时P2PTransportChannel中的状态表已经记录了每条记录所需要花费的成本(涉及到很多因素,比如发出Stun请求到收到应答经过了的时间……)。
当有视频Rtp数据要发送时,检查状态表的第一条记录,如果判断出它的状态是发送就绪,就会用此Connection进行发送。否则直接放弃这个发送任务。也就是说,媒体模块的任务不会受连接状态的影响,只是在要发送是检查状态,如果未连接则放弃发送。
为确保NAT映射和过滤规则不在媒体会话期间超时,ICE会不断通过使用中的候选项对发送Stun连接检查。通俗来说也就是“轮询”,如果STUN的响应超时,则会在增加成本,体现在状态表中就是优先级降低,即P2PTransportChannel状态表是实时的。
WebRTC常用相关API
推荐使用WebRTC兼容库: adapter.js,用来抹平各个浏览器之间的差异
RTCPeerConnection相关
constructor构造函数
通过调用构造函数,返回一个RTCPeerConnection实例,表示本端与对端的一条连接。
const pc = new RTCPeerConnection(?configuration)
为了提高代码的健壮性,可以从多个属性检测构造函数:window.RTCPeerConnection || window.mozRTCPeerConnection || window.webkitRTCPeerConnection
configuration(可选):新建连接的参数,可见MDN文档,常见的是添加iceServers,如
const configuration = {iceServers: [{urls: 'stuns:stun.example.org'}]};
const pc = new RTCPeerConnection(configuration);
不过我们一般使用手动候选ice添加居多
Event事件
onaddstream:收到addstream 事件时调用的事件处理器,当MediaStream 被远端机器添加到这条连接时,该事件会被触发。
onicecandidate:收到 icecandidate 事件时调用的事件处理器。当一个 RTCICECandidate 对象被添加时(setLocalDescription),这个事件被触发。
ontrack:收到track事件时调用,可以从event中获取视频流。
Method方法
createOffer:生成一个offer,它是一个带有特定的配置信息寻找远端匹配机器(peer)的请求。这个方法的前两个参数分别是方法调用成功以及失败的回调函数,可选的第三个参数是用户对视频流以及音频流的定制选项。用于发起方
createAnswer:在协调一条连接中的两端offer/answers时,根据从远端发来的offer生成一个answer。这个方法的前两个参数分别是方法调用成功以及失败时的回调函数,可选的第三个参数是生成的answer的可供选项。用于应答方
setLocalDescription:改变与连接相关的本地描述,分别将offer和answer作为参数传入。例如
const offer = await peer.createOffer();
await peer.setLocalDescription(offer);
const answer = await peer.createAnswer();
await peer.setLocalDescription(answer);
setRemoteDescription:改变与连接相关的对端描述,将接收到对端的SDP作为参数传入
addIceCandidate:手动添加候选ICE,当本机当前页面的 RTCPeerConnection 接收到一个从远端页面通过信号通道发来的新的 ICE 候选地址信息,本机可以通过调用addIceCandidate() 来添加一个 ICE 代理。
close:关闭ICE代理,结束任何正在进行的 ICE 处理和任何活动的流。
createDataChannel:创建一个可以发送任意数据的数据通道(data channel)。常用于后台传输内容, 例如: 图像, 文件传输, 聊天文字, 游戏数据更新包, 等等。
const channel = pc.createDataChannel(label, ?options)
- label:通道标识
- options:配置项
- ordered:信息到达顺序是否和发出顺序一致,默认为true;
- negotiated:默认情况(false)下,一方使用createDataChannel创建通道,另一方使用ondatachannel事件监听,双方进行协商;或者(true)双方调用createDataChannel,使用协定的id;
- id:创建通道的ID,用于双方协定通道,取值范围0-65534;
- maxRetransmits:尝试在不可靠模式下重传数据的次数,默认为空;
- maxPacketLifeTime:不可靠模式下传输消息的最大毫秒数,默认为空;
const dataChannel = RTCPeerConnection.createDataChannel(label, ?options);
channel.onopen = function(event) {
channel.send('Hi back!'); // 发送
}
channel.onmessage = function(event) { // 接收
console.log(event.data);
}
}
addTrack:将一个新的媒体音轨添加到一组音轨中,这些音轨将被传输给另一个对等点。
// 获取视频流
let stream = await navigator.mediaDevices.getUserMedia({ video: true, audio: true });
// 将视频流添加到track
stream.getTracks().forEach(track => {
peer.addTrack(track, stream);
});
getStats:获取WebRTC的状态,发送/接收包的数量、丢包数……可以传入参数( MediaStreamTrack )来控制要获取的数据类型
const peer = new PeerConnection();
setInterval(async () => {
const res = await peer.getStats()
res.forEach(report => console.log(report))
}, 1000)
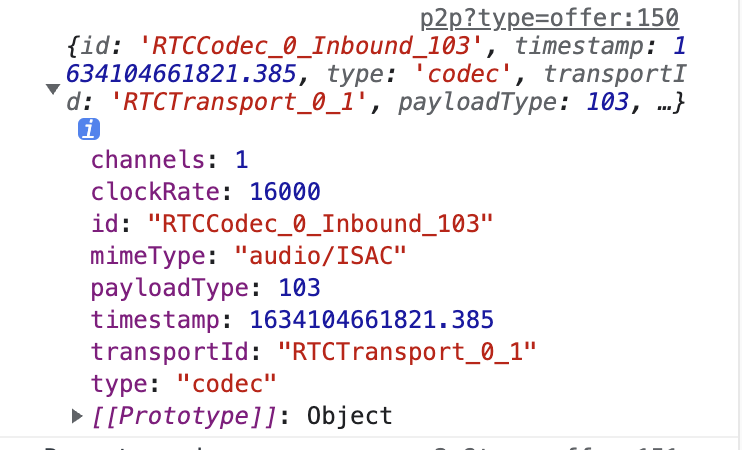
除了RTCPeerConnection实例上有getStats方法,sender和reveiver上也有getStats方法,他们获取的report只有发送/接收的部分,是整体与局部的关系
peer.getSenders()[0].getStats()
media相关
Event事件
ondevicechange:每当媒体设备(例如相机,麦克风或扬声器)连接到系统或从系统中移除时,devicechange 事件就会被触发,这时可以使用enumerateDevices来更新设备列表
Method方法(需要授权)
enumerateDevices:请求一个可用的媒体输入和输出设备的列表,例如麦克风,摄像机,耳机设备等。 返回的 Promise完成时,会带有一个描述设备的数组。
navigator.mediaDevices.enumerateDevices().then(device => {
console.log(device)
})
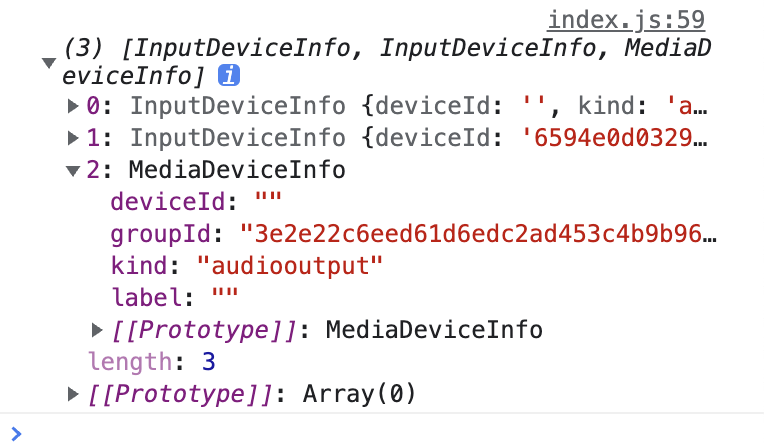
如果两个设备的
groupId相同,说明两个设备是同一台,比如带麦克风的耳机,能检测到输入设备和输出设备,他们两个的groupId相同
getDisplayMedia:提示用户选择捕获的屏幕,返回值是一条视频轨道和可选的音频轨道(参数是媒体流约束,具体描述可见MDN)
// 已经在HTML中声明video标签
const localVideo = document.querySelector("video");
/**
* @description: 向video标签中注入视频流
* @param {*} mediaStream
* @return {*}
*/
function gotLocalMediaStream(mediaStream) {
console.log(mediaStream);
localVideo.srcObject = mediaStream;
}
function screenShare() {
// 屏幕捕捉
navigator.mediaDevices.getDisplayMedia({
video: {
cursor: "always", // 总是显示光标
width: 1920, // 宽度
height: 1080, // 高度
frameRate: 60 // 帧率
},
audio: true
})
.then(gotLocalMediaStream)
}

这里如果是捕获全屏和应用窗口会无法获取声音,捕获浏览器内的标签是可以获取声音的,这里不清楚具体原因,待日后再研究一下
getDisplayMedia:在获取用户授权后,调度用户的摄像机和麦克风,返回视频轨道和音频轨道(均可以来自虚拟源),参数同样是媒体流约束
function photo() {
navigator.mediaDevices
.getUserMedia({
video: { // 视频
width: 640,
height: 480,
frameRate: 15,
facingMode: 'enviroment', // 设置为后置摄像头
/*'user': 前置摄像头
'environment': 后置摄像头
'left': 视频源面向用户但在他们的左边,例如一个对准用户但在他们的左肩上方的摄像机
'right': 视频源面向用户但在用户的右边,例如,摄像机对准用户但在他们的右肩上*/
deviceId: undefined // 设备id
},
audio: true // 音频
})
.then(gotLocalMediaStream)
.catch((error) => console.log("navigator.getUserMedia error: ", error));
}
MediaRecorder相关
constructor构造函数
创建一个新的MediaRecorder对象,对指定的MediaStream 对象进行录制,支持的配置项包括设置容器的MIME 类型 (例如"video/webm" 或者 "video/mp4")和音频及视频的码率或者二者同用一个码率
Const mediaRecorder = new MediaRecorder(stream, ?options);
- Stream: 要录制的流
- Options:
mimeType: 为新构建的MediaRecorder指定录制容器的MIME类型. 在应用中通过调用MediaRecorder.isTypeSupported()来检查浏览器是否支持此种mimeType。audioBitsPerSecond: 指定音频的比特率。videoBitsPerSecond: 指定视频的比特率。bitsPerSecond: 指定音频和视频的比特率。此属性可以用来指定上面两个属性。如果上面两个属性只有其中之一和此属性被指定,则此属性可以用于设定另外一个属性。
Event事件
ondataavailable:当要录制的流有数据时触发
onstart/onpause/onresume/onstop:当开始、暂停、继续、停止事件触发时执行
Method方法
isTypeSupported(static):返回一个Boolean 值,来表示设置的MIME type 是否被当前用户的设备支持。
pause:暂停录制
resume:继续暂停处继续录制
start:开始录制,调用时可以通过给timeslice参数设置一个毫秒值,如果设置这个毫秒值,那么录制的媒体会按照你设置的值进行分割成一个个单独的区块, 而不是以默认的方式录制一个非常大的整块内容。
stop:停止录制,返回一个录制的Blob。
var buffer;
//当该函数被触发后,将数据压入到blob中
function handleDataAvailable(e) {
if (e && e.data && e.data.size > 0) {
buffer.push(e.data);
}
}
function startRecord() {
buffer = [];
//设置录制下来的多媒体格式
var options = {
mimeType: 'video/webm;codecs=vp8'
}
//判断浏览器是否支持录制
if (!MediaRecorder.isTypeSupported(options.mimeType)) {
console.error(`${options.mimeType} is not supported!`);
return;
}
try {
//创建录制对象
mediaRecorder = new MediaRecorder(window.stream, options);
} catch (e) {
console.error('Failed to create MediaRecorder:', e);
return;
}
//当有音视频数据来了之后触发该事件
mediaRecorder.ondataavailable = handleDataAvailable;
//开始录制
mediaRecorder.start(10);
}
实战:一对一音视频通讯(带录屏)
服务端与信令
只有虽然说WebRTC支持P2P,但是需要有一台信令服务器来交换双方的SDP,现在我们就来用Node实现一个信令服务器。
这里选用阿里开源的MidwayJS服务端框架,你可以选择更加轻量级的Express或者Koa框架,都可以通过第三方中间件来实现相同的功能,我这里选择Midway完全是个人偏好。
如果感兴趣可以看一下Midway的文档,或者你钟爱Express可以使用Express+Express-ws来实现完全相同的效果。
客户端能力:
- 提供页面HTML;
- SDP交换;
使用ejs来进行页面渲染
使用模板引擎中间件来进行ejs模板的渲染工作,将路由根目录绑定到页面渲染
这一块相对简单,可以在使用的node框架的官网或者社区找到中间件的文档,根据文档进行配置,然后就可以开始编码工作了(代码非常简单,因为中间件帮我们处理了大部分事情)
@Provide()
@Controller('/')
export class HomeController {
@Inject()
ctx: Context;
@Get('/')
async home() {
await this.ctx.render('home.ejs');
}
}
使用SocketIO作为socker-server来进行SDP交换
socketIO作为一个非常出名的socket框架,其内部提供了非常丰富的API,足够支撑起我们日常开发的大部分需要,这里具体的配置方法就不详写了,可以去官网了解,或许以后我会出相关的教程。
@Provide()
@WSController('/')
export class IndexSocketController {
@Inject()
ctx: Context;
@App()
socket: Application;
@OnWSConnection()
@WSEmit('connection')
// 连接时触发,向客户端提交connection事件
async onConnectionMethod() {
this.ctx.logger.info('on client connect', this.ctx.id);
return 'connection';
}
@OnWSMessage('join')
// 收到消息标识为join时执行
async joinRoom(roomId: string, user: string) {
if ((await this.ctx.to(roomId).allSockets()).size >= 2) {
// 如果房间内的用户数量大于等于二,不可以再加入新的成员
// 并向客户端提交full事件
this.ctx.emit('full', `${roomId} is full!`);
} else {
await this.ctx.join(roomId);
this.ctx.to(roomId).emit('join', `user[ ${user} ] join this room!`);
// 加入房间之后向房间内其他成员提交join事件
// 向用户自身提交joined事件
this.ctx.emit('joined', `join in ${roomId}!`);
}
}
@OnWSMessage('quit')
@WSEmit('result')
async quitRoom(roomId: string, user: string) {
await this.ctx.leave(roomId);
this.ctx.to(roomId).emit('quit', `user[ ${user} ] quit this room!`);
return 'quit success';
}
@OnWSMessage('call')
async call(roomId, data) {
this.ctx.to(roomId).emit('sdp', data);
}
}
(用注解开发真的爽“死”了)

客户端
了解了之前的WebRTC相关API,并且有了信令服务器的加持,我们就可以来进行视频互动的开发了。
为了简化,我们直接就使用模板引擎来渲染视图,不再去单独使用前端框架创建项目了。部分代码借鉴了github的一个开源项目
首先来列举一下客户端的能力
- 基本的音视频通话;
- 录屏;
音视频聊天
进行音视频聊天又分为几个步骤,首先需要初始化ICE
// 初始化ICE
const PeerConnection = window.RTCPeerConnection || window.mozRTCPeerConnection || window.webkitRTCPeerConnection;
!PeerConnection && message.error('浏览器不支持WebRTC!');
const peer = new PeerConnection();
peer.ontrack = e => {
if (e && e.streams) {
// message 是自定义的日志工具
message.log('收到对方音频/视频流数据...');
remoteVideo.srcObject = e.streams[0];
}
};
peer.onicecandidate = e => {
if (e.candidate) {
message.log('搜集并发送候选人');
socket.emit('call', roomId, JSON.stringify({
type: 'ice',
iceCandidate: e.candidate
}));
} else {
message.log('候选人收集完成!');
}
};
然后需要进行交换SDP,这里需要使用Socket来完成
const socket = io('http://localhost:7001')
socket.on('connect_error', () => {
// 连接socket失败
message.error('socket通道初始化失败')
})
// 消息处理
socket.on('connection', () => {
// 连接之后加入房间
socket.emit('join', roomId, username)
})
socket.on('sdp', e => {
const { type, sdp, iceCandidate } = JSON.parse(e)
if (type === 'answer') {
peer.setRemoteDescription(new RTCSessionDescription({ type, sdp }));
} else if (type === 'ice') {
peer.addIceCandidate(iceCandidate);
} else if (type === 'offer') {
const resolve = confirm('接到视频请求,是否接听')
resolve && startLive(new RTCSessionDescription({ type, sdp }));
}
})
当双方都添加了对端的SDP之后就可以开始视频互动了,这里同一封装为startLive方法
async function startLive(offerSdp) {
button.style.display = 'none'
let stream;
try {
message.log('尝试调取本地摄像头/麦克风');
stream = await navigator.mediaDevices.getUserMedia({ video: true, audio: true });
message.log('摄像头/麦克风获取成功!');
localVideo.srcObject = stream;
} catch {
message.error('摄像头/麦克风获取失败!');
return;
}
message.log(`------ WebRTC 流程开始 ------`);
message.log('将媒体轨道添加到轨道集');
stream.getTracks().forEach(track => {
peer.addTrack(track, stream);
});
if (!offerSdp) {
message.log('创建本地SDP');
const offer = await peer.createOffer();
await peer.setLocalDescription(offer);
message.log(`传输发起方本地SDP`);
socket.emit('call', roomId, JSON.stringify(offer));
} else {
message.log('接收到发送方SDP');
await peer.setRemoteDescription(offerSdp);
message.log('创建接收方(应答)SDP');
const answer = await peer.createAnswer();
message.log(`传输接收方(应答)SDP`);
socket.emit('call', roomId, JSON.stringify(answer));
await peer.setLocalDescription(answer);
}
}
效果展示
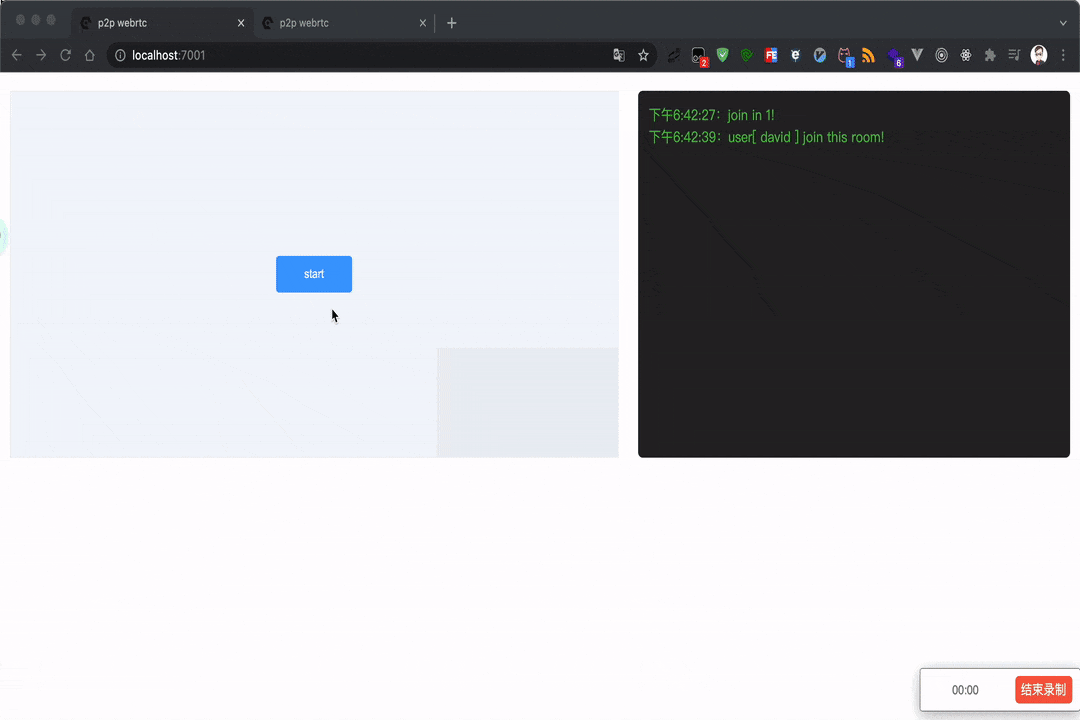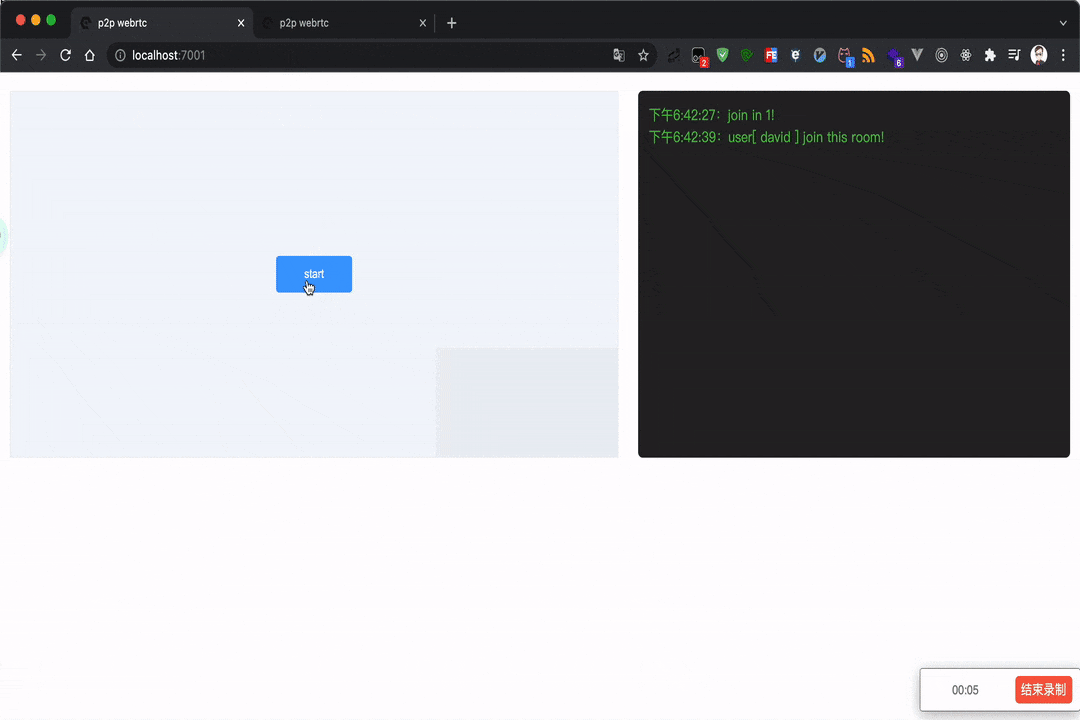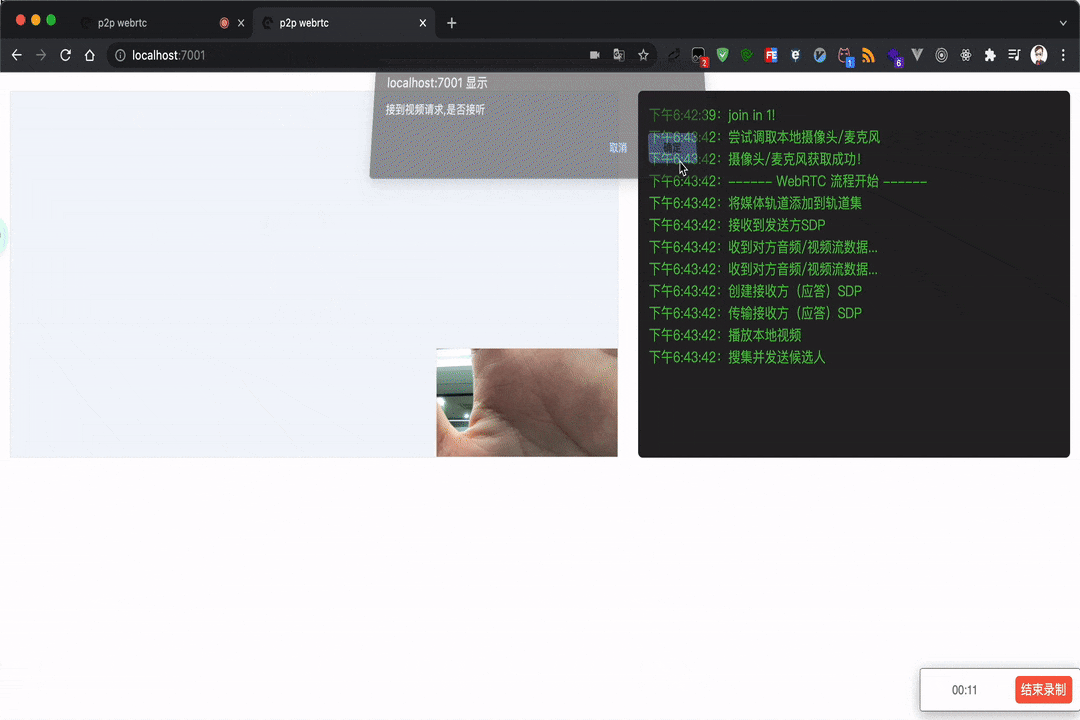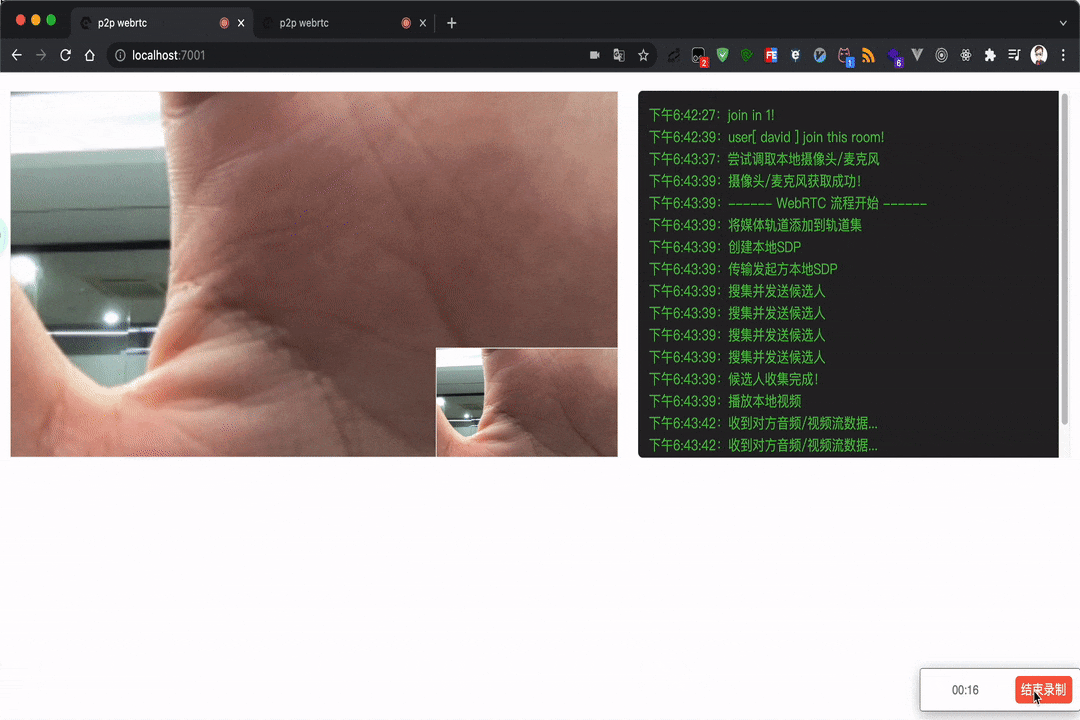
录屏
实现了视频聊天之后我们来添加录屏的功能
之前我们已经介绍了录屏相关的API,这里我们将其添加进我们现有的代码中即可
let buffer, mediaRecorder;
//当该函数被触发后,将数据压入到blob中
function handleDataAvailable(e) {
if (e && e.data && e.data.size > 0) {
buffer.push(e.data);
}
}
// 开始录制
function startRecord() {
buffer = [];
//设置录制下来的多媒体格式
var options = {
mimeType: 'video/webm;codecs=vp8'
}
//判断浏览器是否支持录制
if (!MediaRecorder.isTypeSupported(options.mimeType)) {
message.error(`${options.mimeType} is not supported!`);
return;
}
try {
//创建录制对象
// stream 需要从将视频流保留到全局
mediaRecorder = new MediaRecorder(stream, options);
} catch (e) {
message.error('Failed to create MediaRecorder:', e.message);
return;
}
//当有音视频数据来了之后触发该事件
mediaRecorder.ondataavailable = handleDataAvailable;
//开始录制
mediaRecorder.start(10);
}
// 停止录制
function stopRecord() {
mediaRecorder.stop();
}
// 将录制的视频下载到本地
function downloadRecord() {
var blob = new Blob(buffer, { type: 'video/webm' });
var url = window.URL.createObjectURL(blob);
var a = document.createElement('a');
a.href = url;
a.style.display = 'none';
a.download = new Date().getTime() + '.webm';
a.click();
}
这里只是做了演示,需要根据需求定制录屏的内容
多人音视频互动原理
前面的内容主要是一对一的视频交互,但是在多人场景下,如果客户端之间组成网状结构,WebRTC 就显得有些吃力,客户端要同时进行多路的视频流发送接收,对带宽和 CPU 的要求就高了起来。

这时候就需要通过一台(多台)服务器进行数据流的转发,上面的两两连接的方式也称为 Mesh方案,此外还有MCU 方案和 SFU 方案,这二者的区别在于SFU 仅对视频流进行转发,而 MCU 则会对视频流进行混合处理,因而对服务器的压力更大。
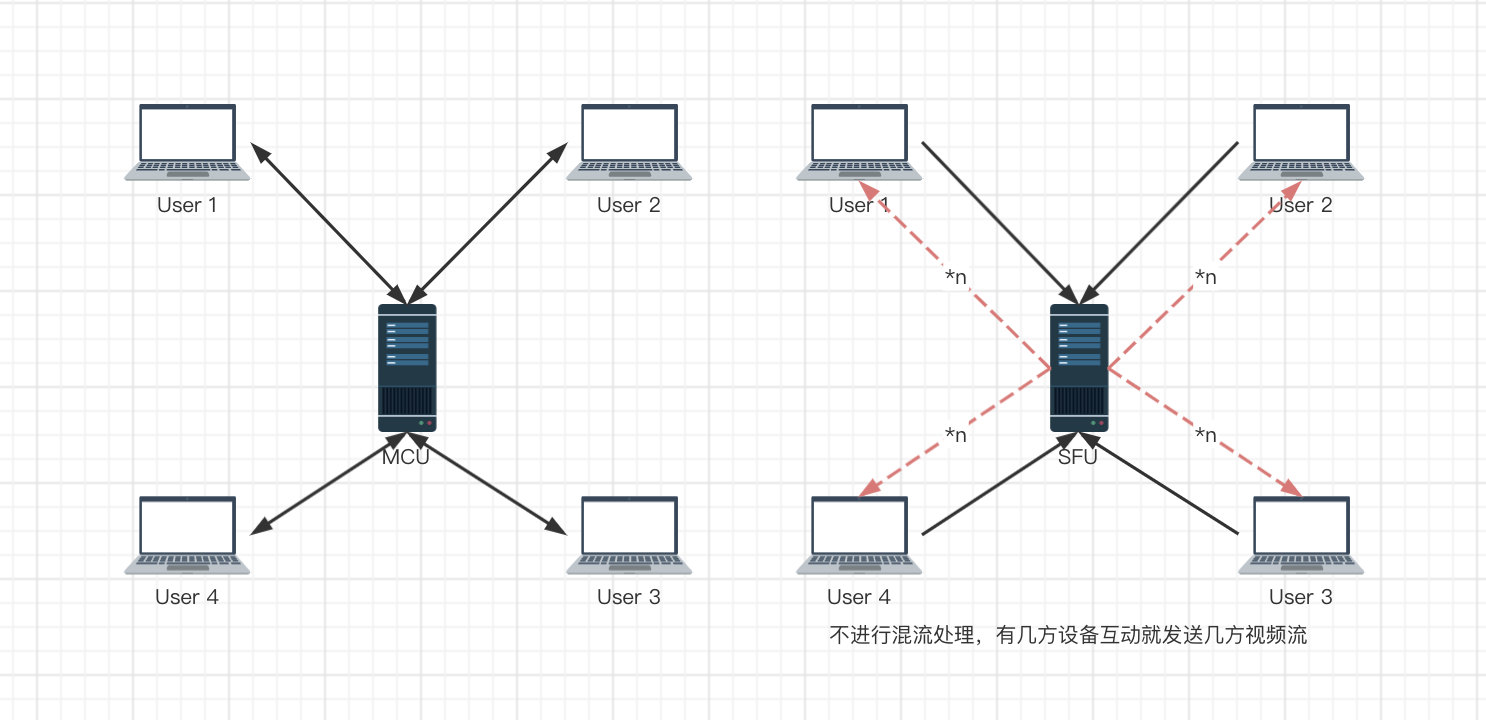
MCU
Multipoint Conferencing Unit,接收每个共享端的音视频流,经过解码、与其他解码后的音视频进行混流、重新编码,之后再将混好的音视频流发送给房间里的所有人。
MCU 的优势大致可总结为如下几点:
- 技术非常成熟,在硬件视频会议中应用非常广泛。
- 作为音视频网关,通过解码、再编码可以屏蔽不同编解码设备的差异化,满足更多客户的集成需求,提升用户体验和产品竞争力。
- 将多路视频混合成一路,所有参与人看到的是相同的画面,客户体验非常好。
MCU 也有一些不足,主要表现为:
- 重新解码、编码、混流,需要大量的运算,对 CPU 资源的消耗很大。
- 重新解码、编码、混流还会带来延迟。
- 由于机器资源耗费很大,所以 MCU 所提供的容量有限,一般十几路视频就是上限了。
SFU
Selective Forwarding Unit,接收终端的音视频流,根据需要转发给其他终端。SFU 在音视频会议中应用非常广泛,尤其是 WebRTC 普及以后。支持 WebRTC 多方通信的媒体服务器基本都是 SFU 结构。
SFU 的优势如下:
- 由于是数据包直接转发,不需要编码、解码,对 CPU 资源消耗很小。
- 直接转发也极大地降低了延迟,提高了实时性。
- 带来了很大的灵活性,能够更好地适应不同的网络状况和终端类型。
当然他也有自己的劣势:
- 由于是数据包直接转发,参与人观看多路视频的时候可能会出现不同步;相同的视频流,不同的参与人看到的画面也可能不一致。
- 参与人同时观看多路视频,在多路视频窗口显示、渲染等会带来很多麻烦,尤其对多人实时通信进行录制,多路流也会带来很多回放的困难。总之,整体在通用性、一致性方面比较差。
综合来看,SFU 是优势最大而劣势又相对不重要的一种架构。
流媒体服务器
在 SFU 架构下,社区上已经出现了很多优秀的开源实现,如Licode、MediaSoup、Medooze、kurento……
Licode
Licode 即可以用作 SFU 类型的流媒体服务器,也可以用做 MCU 类型的流媒体服务器,大多数情况下,使用 Licode 都是 SFU 场景。
Licode 不仅仅是一个流媒体通信服务器,而且还是一个包括了媒体通信层、业务层、用户管理等功能的完整系统,并且该系统还支持分布式部署。
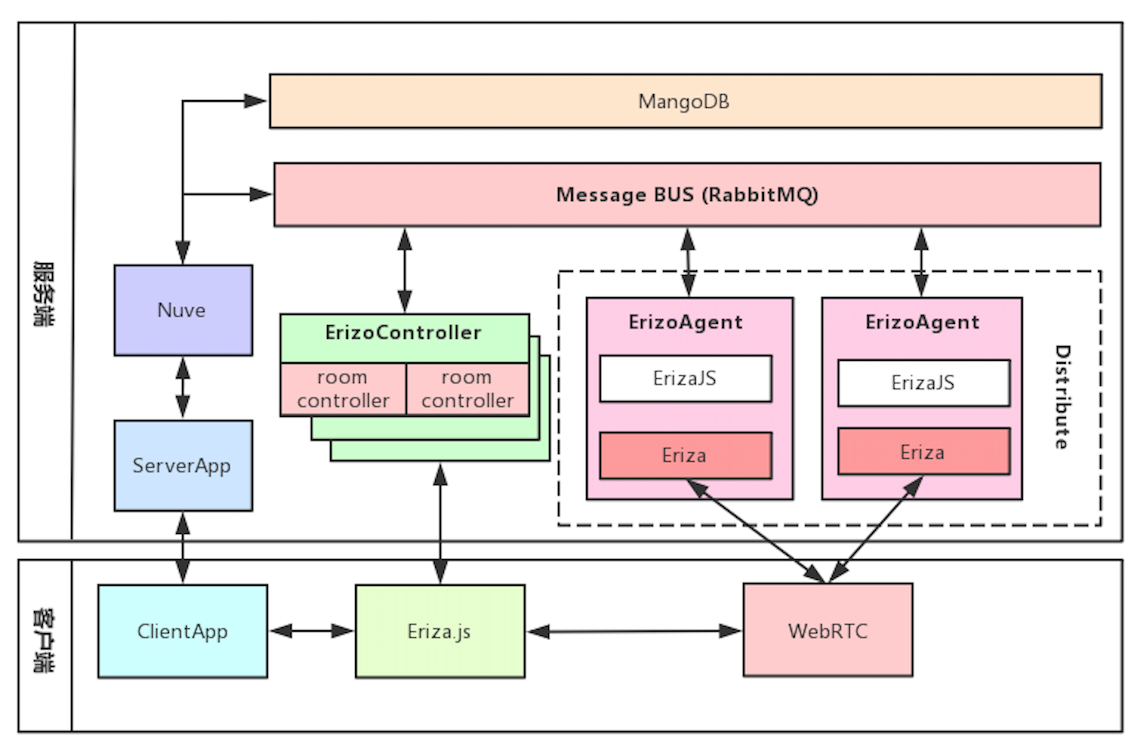
- Nuve 是一个 Web 服务,用于管理用户、房间、产生 token 以及房间的均衡负载等相关工作。它使用 MongoDB 存储房间和 token 信息,但不存储用户信息。
- ErizoController,用于管理控制,信令和非音视频数据都通过它接收。它通过消息队列与 Nuve 进行通信,也就是说 Nuve 可以通过消息队列对 ErizoController 进行控制。
- ErizoAgent,用于音视频流媒体数据的传输,可以分布式布署。ErizoAgent 与 ErizoController 的通信也是通过消息队列,信令消息通过 ErizoController 接收到后,再通过消息队列发给 ErizoAgent,从而实现对 ErizoAgent 进行控制。
Janus-gateway
Janus 是一个非常有名的 WebRTC 流媒体服务器,它是以 Linux 风格编写的服务程序,采用 C 语言实现,支持 Linux/MacOS 下编译、部署,但不支持 Windows 环境
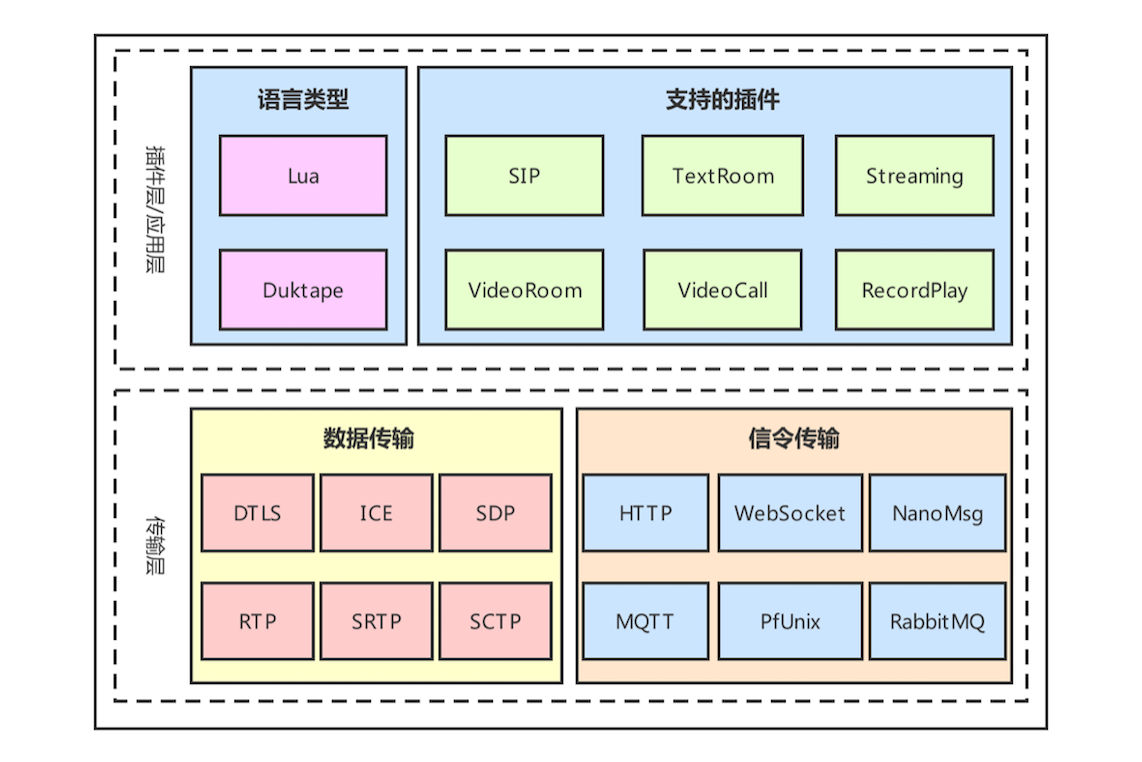
在 Janus 中默认支持的插件包括以下几个。
- SIP:这个插件使得 Janus 成了 SIP 用户的代理,从而允许 WebRTC 终端在 SIP 服务器(如 Asterisk)上注册,并向 SIP 服务器发送或接收音视频流。
- TextRoom:该插件使用 DataChannel 实现了一个文本聊天室应用。
- Streaming:它允许 WebRTC 终端观看 / 收听由其他工具生成的预先录制的文件或媒体。
- VideoRoom:它实现了视频会议的 SFU 服务,实际就是一个音 / 视频路由器。
- VideoCall:这是一个简单的视频呼叫的应用,允许两个 WebRTC 终端相互通信,它与 WebRTC 官网的例子相似(https://apprtc.appspot.com),不同点是这个插件要经过服务端进行音视频流中转,而 WebRTC 官网的例子走的是 P2P 直连。
- RecordPlay:该插件有两个功能,一是将发送给 WebRTC 的数据录制下来,二是可以通过 WebRTC 进行回放。
传输层包括媒体数据传输和信令传输。媒体数据传输层主要实现了 WebRTC 中需要有流媒体协议及其相关协议,如 DTLS 协议、ICE 协议、SDP 协议、RTP 协议、SRTP 协议、SCTP 协议等。
信令传输层用于处理 Janus 的各种信令,它支持的传输协议包括 HTTP/HTTPS、WebSocket/WebSockets、NanoMsg、MQTT、PfUnix、RabbitMQ。不过需要注意的是,有些协议是可以通过编译选项来控制是否安装的,也就是说这些协议并不是默认全部安装的。另外,Janus 所有信令的格式都是采用 Json 格式。
Mediasoup
Mediasoup 是推出时间不长的 WebRTC 流媒体服务器开源库
Mediasoup 把每个实例称为一个 Worker,在 Worker 内部有多个 Router,每个 Router 相当于一个房间。在每个房间里可以有多个用户或称为参与人,每个参与人在 Mediasoup 中由一个 Transport 代理。换句话说,对于房间(Router)来说,Transport 就相当于一个用户。
Transport 有三种类型,即 WebRtcTransport、PlainRtpTransport 和 PipeTransport。
- WebRtcTransport 用于与 WebRTC 类型的客户端进行连接,如浏览器。
- PlainRtpTransport 用于与传统的 RTP 类型的客户端连接,通过该 Transport 可以播放多媒体文件、FFmpeg 的推流等。
- PipeTransport 用于 Router 之间的连接,也就是一个房间中的音视频流通过 PipeTransport 传到另一个房间。
在每个 Transport 中可以包括多个 Producer 和 Consumer。
- Producer 表示媒体流的共享者,它又分为两种类型,即音频的共享者和视频的共享者。
- Consumer 表示媒体流的消费者,它也分为两种类型,即音频的消费者和视频的消费者。
Medooze
Medooze 是一款综合流媒体服务器,它不仅支持 WebRTC 协议栈,还支持很多其他协议,如 RTP、RTMP 等。
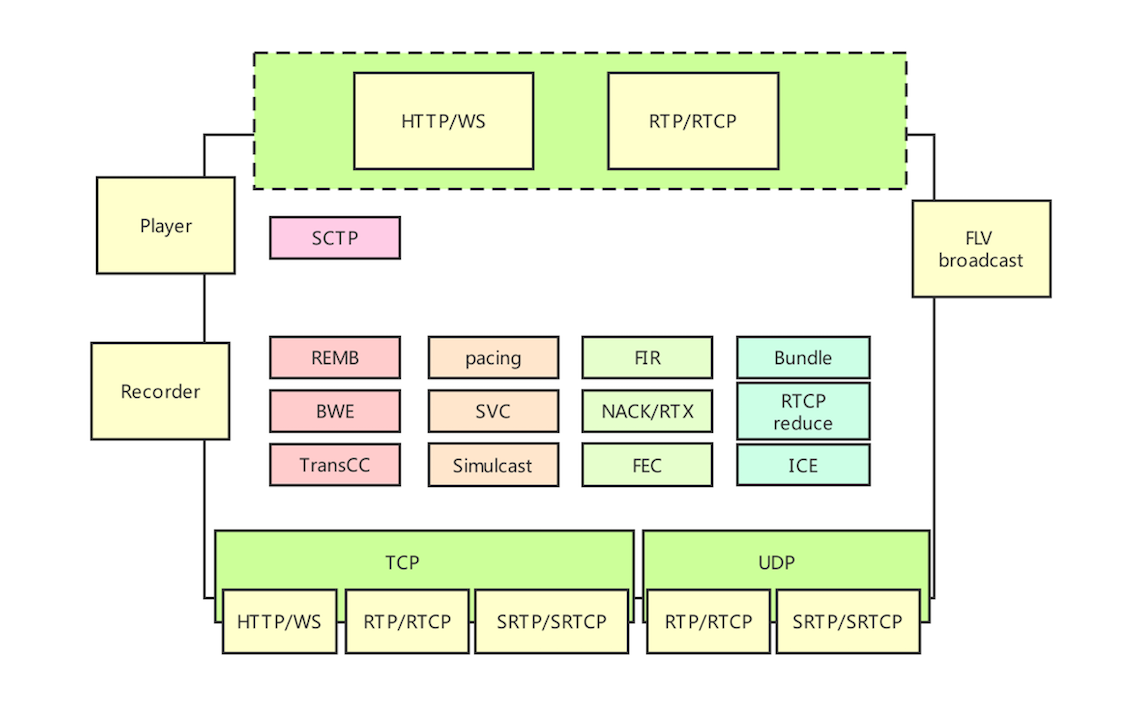
Medooze 支持 RTP/RTCP、SRTP/SRCP 等相关协议,从而可以实现与 WebRTC 终端进行互联。除此之外,Medooze 还可以接入 RTP 流、RTMP 流等,因此你可以使用 GStreamer/FFmpeg 向 Medooze 推流,这样进入到同一个房间的其他 WebRTC 终端就可以看到 / 听到由 GStream/FFmpeg 推送上来的音视频流了。另外,Medooze 还支持录制功能,即上图中的 Recorder 模块的作用,可以通过它将房间内的音视频流录制下来,以便后期回放。
实战:多人音视频互动
之前的 webRTC 架构都只能支撑小规模的会议,如果是大规模的视频互动,如直播等单纯用过 webRTC 是无法支撑的,直播不同于会议,対实时互动的要求并不强烈,更多的关注点在画质、流畅度等方面。
传统直播架构
直播这类传统直播技术一般采用的传输协议是 RTMP 和 HLS

传统的直播架构就是这样,有三个主要部分组成:
- 主播端:主播端由两部分构成,其中一部分就是跟普通用户一样的拉流、解码、播放功能,另一部分的功能是收集主播的音频、视频数据通过 RTMP 推流到 CDN或服务器。
- 信令服务器:信令服务器主要负责聊天消息的转发、礼物的记录、进入离开房间等,这里要注意的是消息的处理,如果 10000 人同时在线,每人发送一条消息,那就是 1 亿次的转发。
- CDN 内容分发网络:CDN 负责直播流的分发,视频流是非常占用带宽的,如果将视频服务全部放在服务器上,就会占用大量带宽导致其他服务受影响。将视频流通过 CDN 进行分发,一方面可以给服务器减负,另一方面可以让视频流更快的传输到用户端进行播放。
主要的流程如下:
- 主播端再开始分享之前先向服务器发送开始直播的信令,信令服务器收到请求之后返回一个推流地址;
- 主播端拿到推流地址之后,开始采集音视频数据,生成 RTMP 消息并向该地址推送 RTMP数据流;
- 移动端直播的流程同 PC 致,③同①
- ④同②
- 客户端向信令服务器发送“进入房间”信令,信令服务器根据用户所在地区,选择一个最近的 CDN边缘节点,告知客户端拉流的地址
- 客户端获得地址之后开始从地址拉取 RTMP 流,然后进行解码播放
RTMP 的兴衰
RTMP,全称 Real Time Messaging Protocol ,即实时消息协议。但它实际上并不能做到真正的实时,一般情况最少都会有几秒到几十秒的延迟,底层是基于 TCP 协议的。
在苹果 HLS 打压之下 RTMP 依旧“屹立不倒”是有原因的
- RTMP 协议底层依赖于 TCP 协议,不会出现丢包、乱序等问题,因此音视频业务质量有很好的保障。
- 使用简单,技术成熟。有现成的 RTMP 协议库实现,如 FFmpeg 项目中的 librtmp 库,用户使用起来非常方便。而且 RTMP 协议在直播领域应用多年,技术已经相当成熟。
- 市场占有率高。在日常的工作或生活中,我们或多或少都会用到 RTMP 协议。如常用的 FLV 文件,实际上就是在 RTMP 消息数据的最前面加了 FLV 文件头。
- 相较于 HLS 协议,它的实时性要高很多。
由于苹果打压,ios 不支持 RTMP,苹果认为 RTMP 在安全方面有缺陷,然后Adobe 就不更新了……
RTMP 的接班人是 HLS,由于是苹果推出的,所以 ios 设备天生支持 HLS,本质是将文件通过 HTTP 下载然后将切片缓存起来,所以 HLS 会有一个等待切片的延迟。
由于浏览器天生支持 HLS,所以不需要安装 Flash;此外,HLS 基于 HTTP,所以可以不受防火墙限制。
HLS 后起之秀
HLS 的架构与 RTMP 相同,唯一区别在于 CDN 分发之前需要由 Convert 服务器将 RTMP 流切割为ts 文件,同时生成m3u8(播放列表)文件,然后用户从距离最近的 CDN节点拉取媒体流了。
安装 ffmpeg
$ brew install ffmpeg
如果没有 Homebrew,先点击链接进入官网进行安装
安装完 ffmpeg 之后我们就可以通过 ffmpeg 把视频文件分割为 HLS 文件了,先准备一个 MP4 文件
执行命令
$ ffmpeg -i test.mp4 -c copy -start_number 0 -hls_time 10 -hls_list_size 0 -hls_segment_filename test%03d.ts index.m3u8
参数意义如下:
- -i:输入文件选项,可以是磁盘文件,也可以是媒体设备。
- -c:copy 输入文件选项,可以是磁盘文件,也可以是媒体设备。
- -start_number:表示 .ts 文件的起始编号,这里设置从 0 开始。当然,你也可以设置其他数字。
- -hls_time:每个 .ts 文件的最大时长,单位是秒。这里设置的是 10s,表示每个切片文件的时长,为 10 秒。当然,由于没有进行重新编码,所以这个时长并不准确。
- -hls_list_size:表示播放列表文件的长度,0 表示不对播放列表文件的大小进行限制。
- -hls_segment_filename:表示指定 TS 文件的名称。表示从0开始用0补全的3位整数为文件名的ts文件序列。 如果想要序列文件名为test_0001.ts等等的话,就是test_%04d.ts。
- index.m3u8,表示索引文件名称。
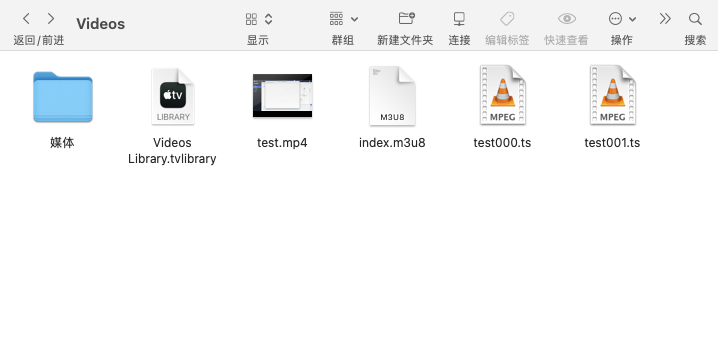
.m3u8 文件内容如下
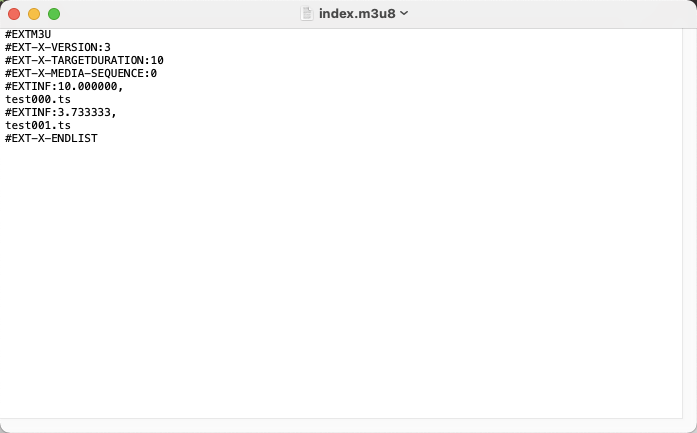
从第二行开始的意义分别是:版本信息、每个分片的目标时长、分片起始编号、第一个分片实际时长、第一个分片文件、第二个实际分片时长、第二个分片文件
#后面跟的是 TAG,主要的 TAG 有:
- EXTM3U 表示文件是第一个扩展的 M3U8 文件,此 TAG 必须放在索引文件的第一行。
- EXT-X-VERSION: n 表示索引文件支持的版本号,后面的数字 n 是版本号数字。需要注意的是,一个索引文件只能有一行版本号 TAG,否则播放器会解析报错。
- EXT-X-TARGETDURATION: s 表示 .ts 切片的最大时长,单位是秒(s)。
- EXT-X-MEDIA-SEQUENCE: number 表示第一个 .ts 切片文件的编号。若不设置此项,就是默认从 0 开始的。
- EXTINF: duration, title 表示 .ts 文件的时长和文件名称。文件时长不能超过#EXT-X-TARGETDURATION中设置的最大时长,并且时长的单位应该采用浮点数来提高精度。
这里的 TS 格式并不是我们现在的TypeScript,而是最开始应用于数字电视的文件格式,原始的文件格式很复杂,苹果 HLS 协议对 TS流做了精减只保留了最基本的 PAT 和PMT。所以 HLS 由 PAT+PMT+TS 数据流组成,TS数据中的视频数据采用 H264 格式,音频数据采用 AAC/MP3 格式
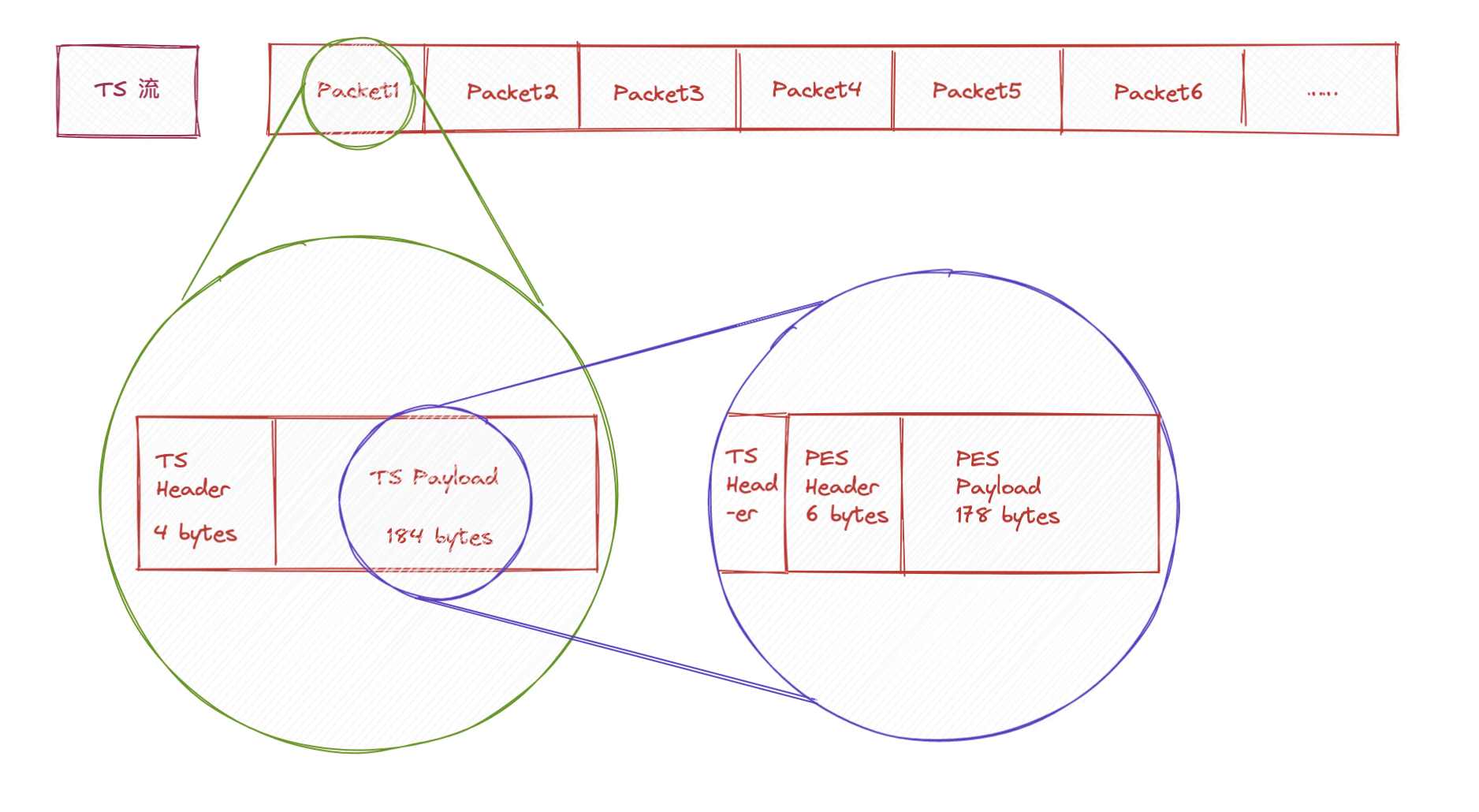
TS 数据流由 TS Header 和 TS Payload 组成,TS Payload内部又由 PES Header 和 PES Payload 组成,PES Payload 就是真正的音视频流
TS Header 构成如下

PES Header 构成如下

FLV 新兴网络视频格式
RTMP 和 HLS 区别在于:RTMP 延迟要小,因为不需要切片;RTMP 底层基于 TCP 不需要开发人员开率丢包和乱序问题
FLV 和 RTMP 是“近亲”关系,FLV文件格式如下
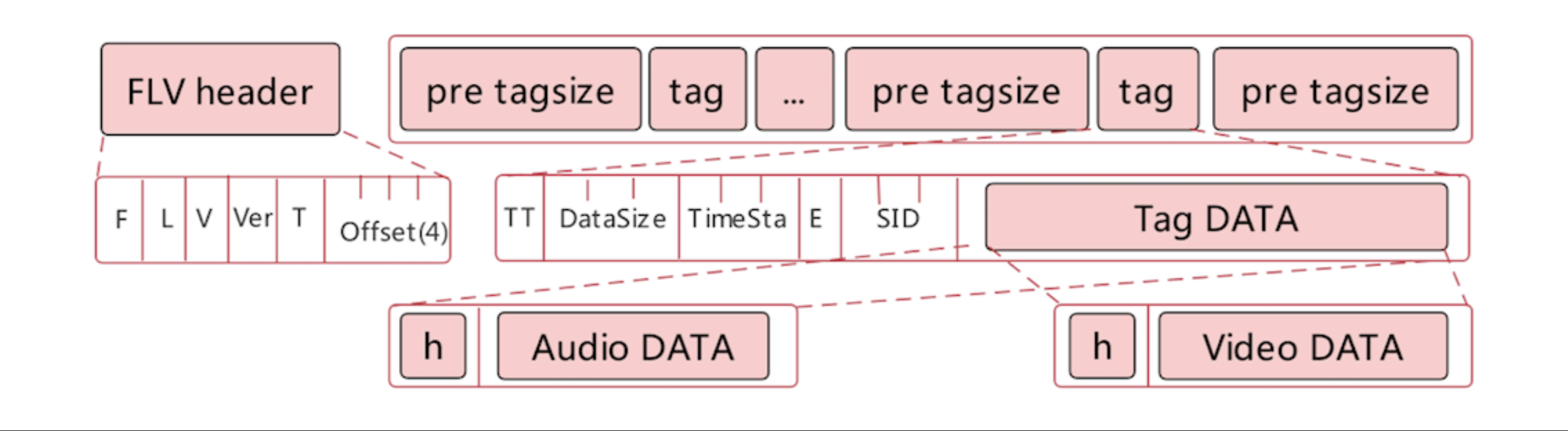
FLV 格式文件适合录制,为什么?
FLV 是一个流式文件,可以将音视频数据随时添加到 FLV 文件的末尾,而不会破坏文件的整体结构。
像 MP4、MOV 等媒体文件格式都是结构化的,也就是说音频数据与视频数据是单独存放的。当服务端接收到音视频数据后,如果不通过 MP4 的文件头,根本就找不到音频或视频数据存放的位置。
使用 FLV 进行视频回放也特别方便,将生成好的 FLV 直接推送到 CDN 云服务,在 CDN 云服务会将 FLV 文件转成 HLS 切片,这样用户就可以根据自己的终端选择使用 FLV 或 HLS 协议回放录制好的视频。
最简单的直播系统
现在我们抛开先前的 CDN 等,仅保留最基础的推流、拉流功能,实习哪一个简易的直播系统,我们需要用到 Nginx、FFmpeg 等工具
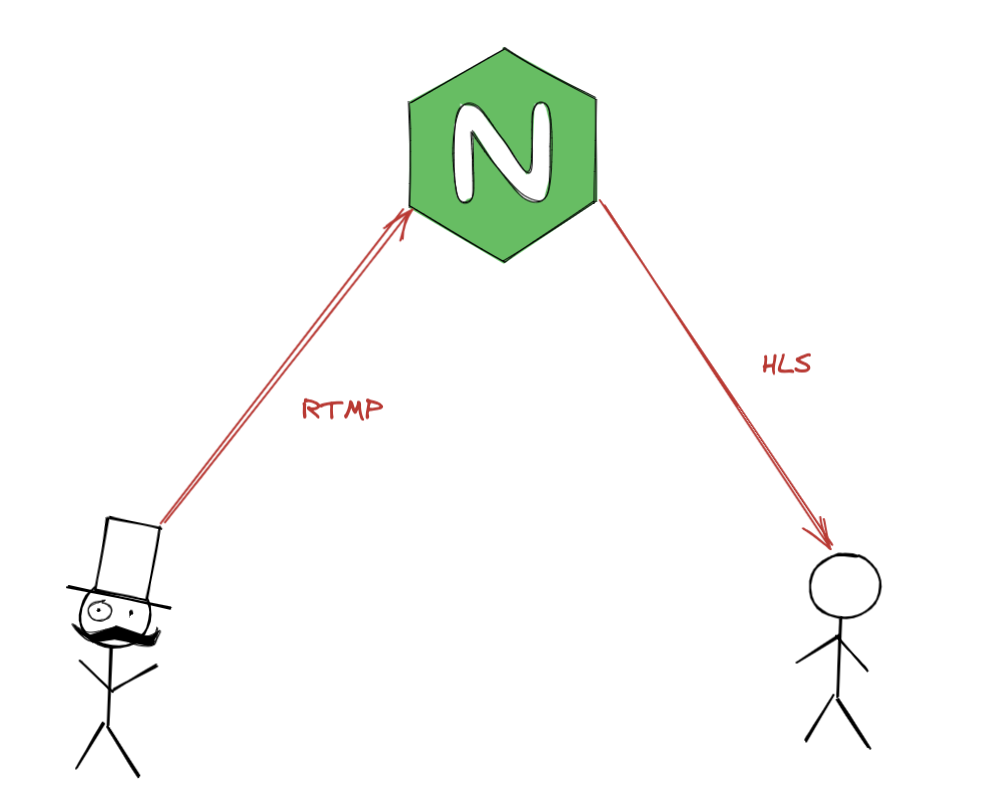
之所以选择 Nginx是因为他的优越性能,并且Nginx 有现成的 RTMP 推拉流模块。
(如果实在懒得操作,后面贴心提供了docker 镜像🐳)
Nginx
首先下载Nginx 软件,使用命令获取
$ wget -c http://nginx.org/download/nginx-1.17.4.tar.gz
$ tar -zvxf nginx-1.17.4.tar.gz
然后我们还需要 Nginx RTMP Module 和 OpenSSL,RTMP Module 是 Nginx 的一个插件,由于音视频的常用场景并不广泛,所以并没有集成进 Nginx 软件,而是以插件的形式提供,OpenSSL 用于数据传输的安全。
OpenSSL
使用命令下载 OpenSSL 的源码
$ wget -c https://www.openssl.org/source/openssl-1.1.1.tar.gz --no-check-certificate
$ tar -zvxf openssl-1.1.1.tar.gz
Nginx RTMP Module
Nginx RTMP Module 的常用功能:
- 支持 RTMP/HLS/MPEG-DASH 协议的音视频直播
- 支持 FLV/MP4 文件的视频点播功能
- 支持以推拉流方式进行数据流的中继
- 支持将音视频流录制成多个 FLV 文件
这个模块需要从 github 拉取源码
git clone https://github.com/arut/nginx-rtmp-module.git
编译
第一步需要先对 OpenSSL 进行编译,进入刚才解压好的openssl-1.1.1目录
$ ./config
$ make $$ sudo make install
可能会出现编译失败的情况,大部分是因为缺少某些库造成的,根据报错提示安装缺失的库即可
第二步编译 Nginx,进入刚才解压的 Nginx 源码目录
$ ./configure --prefix=/usr/local/nginx --add-module=../nginx-rtmp-module --with-http_ssl_module --with-debug
$ make && sudo make install
参数的意思如下:
- prefix:指定将编译好的 Nginx 安装到哪个目录下。
- add-module:指明在生成 Nginx Makefile 的同时,也将 nginx-rtmp-module 模块的编译命令添加到 Makefile 中。
- http_ssl_module:指定 Ngnix 服务器支持 SSL 功能。
- with-debug:输出 debug 信息。
Nginx.conf
在 Nginx 安装之后,在/usr/local/nginx/conf/目录下的 nginx.conf 文件下新增配置
...
events {
...
}
#RTMP 服务
rtmp {
server{
#指定服务端口
listen 1935; //RTMP协议使用的默认端口
chunk_size 4000; //RTMP分块大小
#指定RTMP流应用
application live //推送地址
{
live on; //打开直播流
allow play all;
}
#指定 HLS 流应用
application hls {
live on; //打开直播流
hls on; //打开 HLS
hls_path /tmp/hls;
}
}
}
http {
...
location /hls {
# Serve HLS fragments
types {
application/vnd.apple.mpegurl m3u8;
video/mp2t ts;
}
root /tmp;
add_header Cache-Control no-cache;
}
...
}
...
然后使用 ffmpeg 进行视频共享
$ ffmpeg -re -i tesy.mp4 -c copy -f flv rtmp://localhost:1935/live/stream
命令的意义如下:
- -re,代表按视频的帧率发送数据,否则 FFmpeg 会按最高的速率发送数据;
- -i ,表示输入文件;
- -c copy,表示不对输入文件进行重新编码;
- -f flv,表示推流时按 RTMP 协议推流;
- rtmp://……,表示推流的地址,url 除去协议之外还有三部分,服务器地址端口/应用名/串流秘钥(相当于房间号)。
除了使用 ffmpeg 之外我们还可以利用 OBS 来进行推流,将 FFmpeg 的地址填入 OBS 的推流配置中

我们可以找一个视频文件来试一下,然后可以使用VLC、Flash 等工具来观看视频,播放地址和刚才的推流地址一致

docker 镜像
结束了上面的流程,来填一下坑,拉取docker镜像
$ docker pull mugennsou/nginx-http-flv
这个镜像中已经配置好了 nginx 的配置,可以直接使用,它里面默认的应用名是 demo
如果想自定义的的话可以通过文件挂载将我们自定义的配置文件进行替换
配置文件内容如下
server {
listen 1935;
application live {
live on;
gop_cache on;
}
application hls {
live on;
hls on;
hls_path /tmp/hls;
}
application dash {
live on;
dash on;
dash_path /tmp/dash;
}
}
docker启动命令如下
$ docker run -d --name nginx-http-flv -v "${PWD}/rtmp.conf":/etc/nginx/conf.d/rtmp/rtmp.conf -p 1935:1935 -p 80:80 mugennsou/nginx-http-flv
PWD是指的当前所在目录,我们要在当前目录下创建 rtmp.conf 文件,写入上面的 nginx 配置,才能进行正确的挂载。担心出错可以不使用 PWD,直接使用绝对路径
除了 RTMP 服务之外,这个镜像还配置了 HLS,可以通过 flv.js 等工具在浏览器实现播放,地址为http://localhost/live?app=live&stream=stream1,两个参数就是上面的应用和串流密钥,如果想要修改 http-flv 相关的配置,可以自行去镜像里面提取出文件来修改之后挂载进容器。他也内置了基于flv.js 的视频预览页面,直接打开 localhost即可观看。
“万人直播”
现在99%的传统直播业务都是基于 CDN 实现的,各大云服务商提供的 CDN 服务都支持实时音视频业务了,推流和拉流的过程可以完全由 CDN 节点来完成,主服务器只需要处理传统业务逻辑
CDN 就近接入
众所周知 CDN 实现加速的原理是在全国各大城市部署分发服务器,各个服务器之间的内容是一致的,比如:某网站的主机位于杭州,某用户在北京访问该网站,访问在北京的加速节点和杭州的主机哪个速度更快就不用说了吧。
为什么 CDN 可以实现就近接入呢?——智能DNS 解析
不了解 DNS 解析的可以点击链接了解一下。
通过 DNS解析可以获取到域名对应的 IP 地址,但只这样还不够,如果检测到域名对应多个 IP,会随机选择一个返回用户,但是智能 DNS 会判断用户的 IP,根据所在地区和服务商选择最近的 CDN 节点地址返回给用户。
所谓的万人架构和原本的 RTMP流媒体服务器没有什么区别,只是替换为了 CDN 加速。
【完】
参考资料:《从 0 打造音视频直播系统》——极客时间·李超