



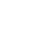



前戏
在开始了解多线程之前先来了解一下程序任务按照性能的分类,从性能方面来看,计算机程序主要分为两个维度,CPU密集型(也叫计算密集型)和UO密集型。
CPU密集型,顾名思义就是对CPU的要求较高,大部分时间都花费在了在计算上,例如计算圆周率,视频解码等;IO密集型当然就是把大量的时间都浪费在了等待IO上,例如文件读写,网络IO……
为了解决CPU密集型带来问题,多线程方案应运而生,通过开启多个线程来充分利用CPU的多个核心。
Nodejs以异步单线程而闻名,也常常因为单线程而被人诟病,为了解决这个问题,Node.js v10.5.0 通过 worker_threads 模块引入了实验性的 “worker 线程” 概念,并从 Node.js v12 LTS 起成为一个稳定功能。如果使用过浏览器中的web_worker也许会更容易理解worker_threads。
发展史
在引入worker之前,node也给出了多个方案来适应CPU密集型应用
- child_process模块:用来创建子进程,并执行一些任务
- cluster模块:创建多个工作进程
- Napa.js第三方模块
由于受限于性能、额外引入等等问题,这下方案都没有被最终采纳。于是,最终的解决方案worker_threads诞生了
工作线程对于执行 CPU 密集型的 JavaScript 操作很有用。 它们对 I/O 密集型的工作帮助不大。 Node.js 内置的异步 I/O 操作比工作线程更高效。
child_process
开启子线程主要依靠的是child_process.fork(modulePath[, args][, options]),接收三个参数,运行的子模块路径、参数、更多配置信息,具体使用方法如下图

衍生的 Node.js 子进程独立于父进程,除了两者之间建立的 IPC 通信通道。 每个进程都有自己的内存,具有自己的 V8 实例。 由于需要额外的资源分配,不建议衍生大量子 Node.js 进程。
// parent.js
const childProcess = require('child_process')
const child = childProcess.fork(__dirname + '/son_process.js')
child.on('message', m => {
console.log('message from child: ' + JSON.stringify(m));
})
child.send({ from: 'parent' });
// son_process.js
process.on('message', (m) => {
// you can do anything at here
console.log('message from parent: ' + JSON.stringify(m));
})
process.send({ from: 'child' });
child_process模块下另外一个常见的功能,child_process 模块提供了以与 popen(3) 类似但不完全相同的方式衍生子进程的能力,通过shell命令来执行一些操作,例如可以用作githooks等。 此功能主要由 child_process.spawn() 函数提供:
child_process.spawn(command[, args][, options])接收3个参数,要执行的命令、参数、配置,具体的信息见下图

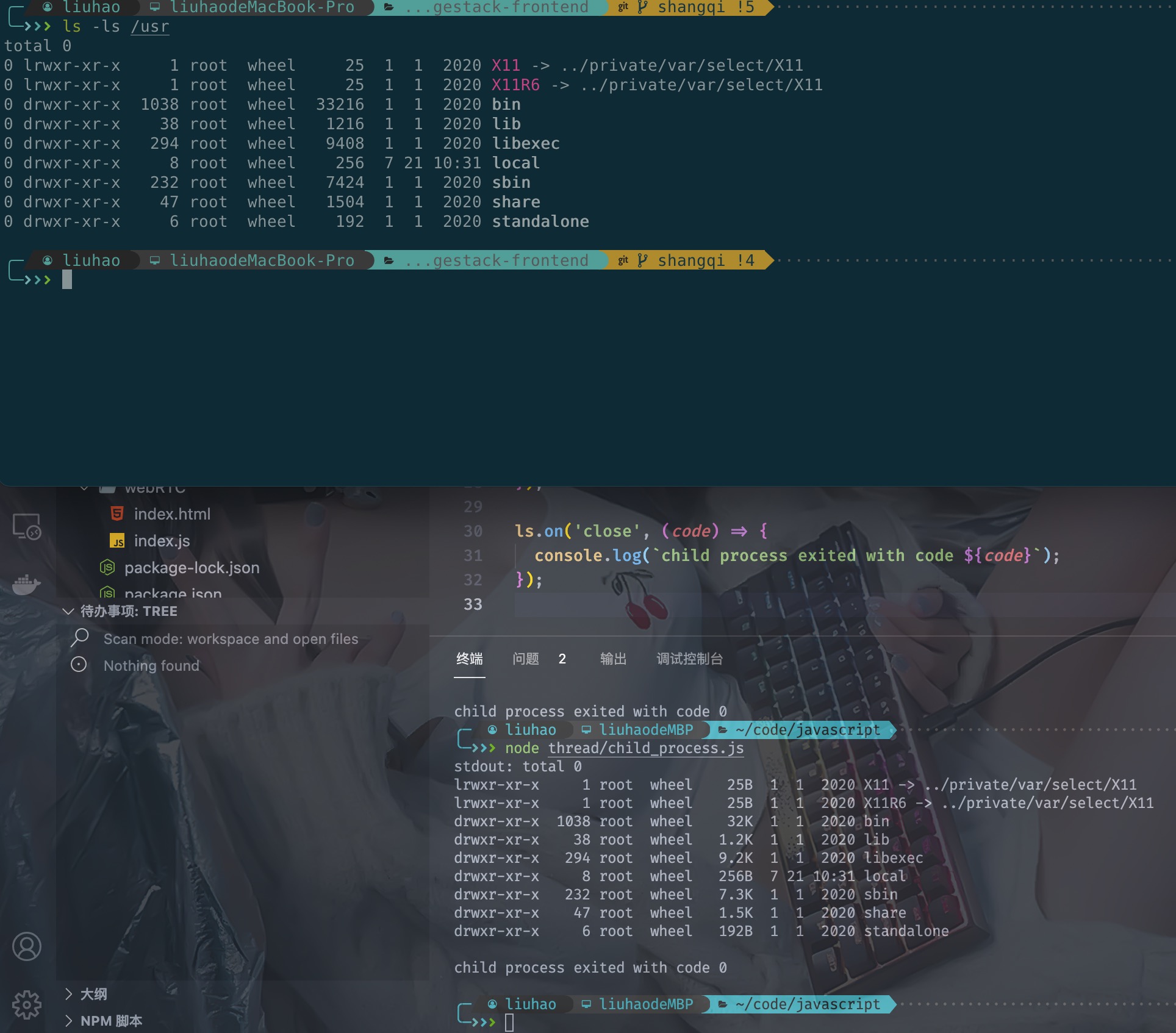
示例
const { spawn } = require('child_process');
const ls = spawn('ls', ['-lh', '/usr']);
ls.stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
});
ls.stderr.on('data', (data) => {
console.error(`stderr: ${data}`);
});
ls.on('close', (code) => {
console.log(`child process exited with code ${code}`);
});
更多child_process用法见node官网
cluster
Node.js 的单个实例在单个线程中运行。 为了利用多核系统,集群模块可以轻松创建共享服务器端口的子进程。
集群这里直接上代码可能会看的更清晰一些,已经添加注释,仔细阅读一下代码,就能看清楚cluster是怎么开启多个进程的
首先我们先来编写应用服务,这里使用koa作为server端框架
const Koa = require('koa2');
const app = new Koa();
app.use(async (ctx, next) => {
// 制造随机错误, 子进程会在出错时技=结束
Math.random() > 0.9 ? func() : 'a'
await next();
ctx.response.type = 'text/html';
ctx.response.body = `<h1>Hello Koa2</h1>`
})
// console.log(module.parent);
// 如果是主模块就监听3000
if (!module.parent) {
app.listen(3000, () => {
console.log('listening port 3000');
})
} else {
// 不是主模块就导出server代码
module.exports = app
}
然后是集群应用
const os = require('os');
const cluster = require('cluster');
const process = require('process');
// 计算机CPU核心数
const cpus = os.cpus().length;
console.log("cpus: ", cpus);
// map的形式记录worker及对应的进程pid {8035: Worker}
const workers = {};
// 主进程用来管理子进程
if (cluster.isMaster) {
// 在主进程添加death事件监听,当线程挂掉时重启一个线程
cluster.on('death', worker => {
// 创建子进程
worker = cluster.fork();
workers[worker.pid] = worker;
});
// 根据CPU数量来建立进程
for (let i = 0; i < cpus; i++) {
const worker = cluster.fork();
workers[worker.pid] = worker;
}
} else {
// 子进程用来执行server端逻辑
const app = require('./app');
app.use(async (ctx, next) => {
console.log('worker' + cluster.worker.id + 'PID: ' + process.pid);
})
app.listen(3000)
}
// 结束时kill掉workers中保存的所有进程
process.on('SIGTERM', () => {
for (let pid in workers) {
process.kill(pid)
}
process.exit(0)
})
// 引入测试文件
require('./test')
// test.js
// 自动化测试,每秒钟请求接口
const http = require('http');
setInterval(async () => {
try {
await http.get('http://localhost:3000')
} catch (error) {
console.log(error);
}
}, 1000)
运行看一下结果
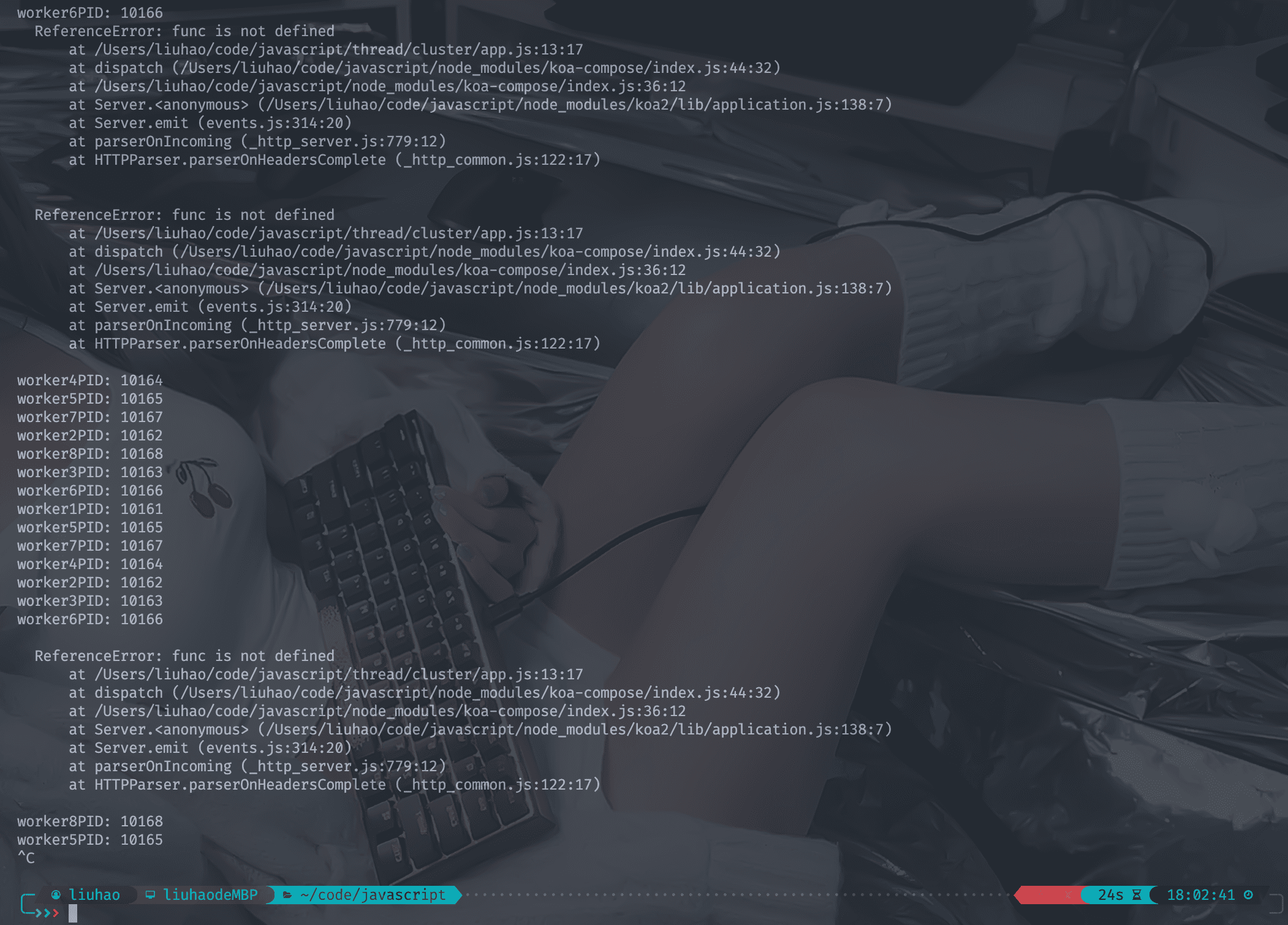
可以看到开启了8个进程在同步运行
cluster比起child_process最大的优势就是可以监听多个相同端口。实际上,cluster新建的工作进程并没有真正去监听端口,在工作进程中的net server listen函数会被hack,工作进程调用listen,不会有任何效果。
监听端口工作交给了主进程,该端口对应的工作进程会被绑定到主进程中,当请求进来的时候,主进程会将请求的套接字下发给相应的工作进程,工作进程再对请求进行处理。
详情可以看node官网
worker_threads
worker_threads在使用过程中和浏览器的web worker是极为相似的,来看一段最简单的worker_threads的示例
const { Worker, isMainThread, parentPort } = require('worker_threads');
// isMainThread: 该对象用于区分是主线程(true)还是工作线程(false)
if (isMainThread) {
// Worker对象 必填参数 __filename(文件路径),该文件会被 worker 执行
const worker = new Worker(__filename);
// 工作进程监听 message 事件
worker.on('message', (msg) => { console.log(msg); });
} else {
// parentPort: 该对象的 postMessage 方法用于 worker 线程向主线程发送消息
parentPort.postMessage('Hello world!');
}
是不是和web worker很相似,再来通过一段实战代码加深一下。这里选用斐波那契数列来对比单线程和多线程的运行状态
单线程状态下
const fib = (times) => {
if (times === 0) return 0;
else if (times === 1) return 1;
else return fib(times - 1) + fib(times - 2)
}
// 记录当前时间戳
const now = new Date().getTime();
const result1 = fib(40);
console.log('result1用时:' + (new Date().getTime() - now));
const result2 = fib(40);
console.log('result2用时:' + (new Date().getTime() - now));
const result3 = fib(40);
console.log('result3用时:' + (new Date().getTime() - now));
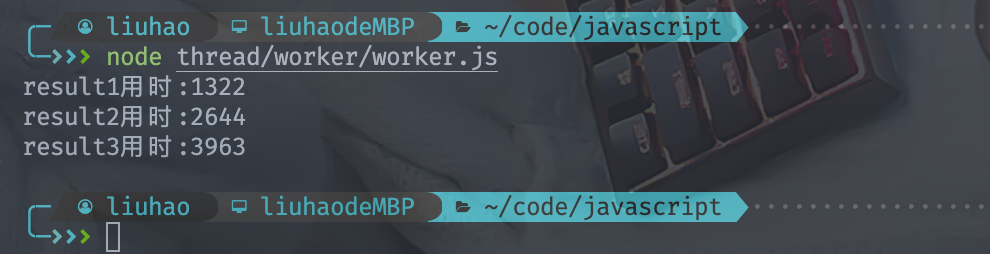
三次斐波那契依次计算,最终用时3963ms
多线程状态下
const { Worker,
isMainThread,
parentPort,
workerData
} = require('worker_threads');
if (isMainThread) {
const now = new Date().getTime();
const worker1 = new Worker(__filename, { workerData: 40 })
worker1.on('message', () => {
console.log('result1用时:' + (new Date().getTime() - now))
})
const worker2 = new Worker(__filename, { workerData: 40 })
worker2.on('message', () => {
console.log('result2用时:' + (new Date().getTime() - now))
})
const worker3 = new Worker(__filename, { workerData: 40 })
worker3.on('message', () => {
console.log('result3用时:' + (new Date().getTime() - now))
})
} else {
const fib = (times) => {
if (times === 0) return 0;
else if (times === 1) return 1;
else return fib(times - 1) + fib(times - 2)
}
const times = workerData
const result = fib(times)
parentPort.postMessage(result)
}
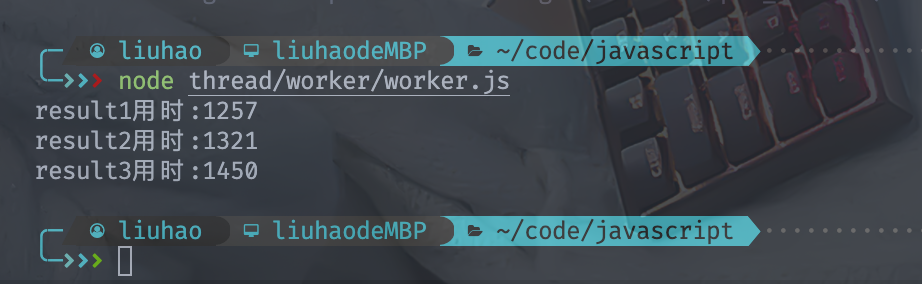
三个线程同步执行,分别用了一秒左右执行完毕,共用时1450ms



