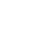



生成海报无非有两种形式:
- 浏览器通过html2canvas 或者 canvas绘制,然后导出图片;
- NodeJS 通过 puppeteer 渲染页面,然后进行截图。
puppeteer就是我们说的无头浏览器:Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。Puppeteer 默认以 headless 模式运行,但是可以通过修改配置文件运行“有头”模式。
都是先渲染再截图,那为什么不直接在浏览器上进行呢?
直接使用 html2canvas 会存在动态图片跨域的问题,而且不同的设备上会存在兼容性问题。当然也有自己的优势, 完全解放服务器,由前端独立生成,定制化样式强。
使用 puppeteer 方案的优势在于复用性强,个性化定制能力强,缺点是性能可能会受限。
我们基于 puppeteer 方案来实现一个生成分享海报的平台。
首先最艰难的一步安装 puppeteer,安装的过程中会出现千奇百怪的问题,不是 Node 版本太高就是 Node 版本太低,这个根据自己的实际情况百度解决即可。安装太慢可能需要科学一下。
$ npm install puppeteer --save
puppeteer 常用的 API 如下:
- Puppeteer.launch:连接 puppeteer 和 Chromium,返回一个 Browser 实例;
- Browser.newPage:打开一个新页面,返回当前页面实例 Page;
- Browser.close:关闭 Chromium;
- Page.goto:页面地址跳转;
- Page.close:关闭页面。
使用 koa 启动 http 服务程序,koa 相关的操作就不再赘述了,网上教程一堆一堆的。
安装完相关依赖之后新建 server.js 文件,用于启动 koa 服务。
import Koa from 'koa'
import Router from '@koa/router'
import puppeteer from 'puppeteer'
const app = new Koa()
const router = new Router()
const browser = await puppeteer.launch(); // 初始化浏览器实例
router.get('/poster', async (ctx, next) => {
const start = new Date().getTime()
const page = await browser.newPage(); // 打开新页面
await page.goto('https://www.baidu.com'); // 跳转地址
const image = await page.screenshot({ path: 'screenshot.png' }); // 截图
await page.close(); // 关闭标签
const end = new Date().getTime()
ctx.set('Content-Type', 'image/png');
console.log(end - start + 'ms'); // 7170ms 根据网速快慢不固定
ctx.body = image;
})
app.use(router.routes())
app.listen(3030, () => {
console.log('start: listening on 3030')
})
上面的示例我们加载了百度的主页来生成截屏,这里响应会很慢,正常情况下应该使用静态文件来渲染。
由于 puppeteer 的操作比较吃性能,所以我们可以通过池化来进行优化,可以通过 generic-pool库来创建实例池。
$ npm install generic-pool --save
新建 pool.js
import puppeteer from 'puppeteer'
import genericPool from 'generic-pool'
const createPuppeteerPool = ({
max = 10, // 最大容量
min = 1, // 最小容量
idleTimeoutMills = 30000, // 保持空闲不被回收的最小时间
maxUses = 50, // 最大使用数
testOnBorrow = true, // 交付实例之前是否经过验证
puppeteerArgs = {},
validator = () => Promise.resolve(true),
...otherConfig
} = {}) => {
// factory 对象
const factory = {
create: () => puppeteer.launch(puppeteerArgs).then(instance => {
instance.useCount = 0
return instance
}),
destroy: instance => instance.close(),
validate: instance => validator(instance)
.then(valid => Promise.resolve(valid && instance.useCount < maxUses)) // 未超过最大使用数时通过验证
}
// config 对象
const config = {
max,
min,
idleTimeoutMills,
testOnBorrow,
...otherConfig
}
// Pool 实例
const pool = genericPool.createPool(factory, config)
const genericAcquire = pool.acquire.bind(pool) // 保存原始的 acquire 方法
// 重写acquire方法, 每次调用使用数+1
pool.acquire = () =>
genericAcquire().then(instance => {
instance.useCount += 1
return instance
})
pool.use = fn => {
let resource
return pool
.acquire()
.then(r => {
resource = r
return r
})
.then(fn)
.then(result => {
pool.release(resource)
return result
}, err => {
pool.release(resource)
throw err
})
}
console.log('pool init finished');
return pool
}
export default createPuppeteerPool
细细读下来每一行代码做了什么应该基本都能看懂,其大致的作用是
- 5-12 行,结构参数并设置默认值;
- 15-23 行,声明generic-pool 创建链接池所需的 factory 对象,具体的要求在他的 npm 描述里面都很详细;
- 26-32 行,根据结构出来的参数,声明 generic-pool 创建连接池的配置对象;
- 35 行,创建Pool 实例;
- 36 行,保留原始的 pool.acquire 方法,因为后面我们要自重写这个方法;
- 39-43行,重写pool.acquire方法,在原有功能的基础上,在每次使用实例时使用次数统计
+1; - 45-62 行,根据原始的pool.use 逻辑进行重写,将原有的失败逻辑进行替换。原来的逻辑是失败时销毁实例不再提供给其他调用者使用,我们重写为出错时释放资源继续使用。
/**
* [use method, aquires a resource, passes the resource to a user supplied function and releases it]
* @param {Function} fn [a function that accepts a resource and returns a promise that resolves/rejects once it has finished using the resource]
* @return {Promise} [resolves once the resource is released to the pool]
*/
use(fn, priority) {
return this.acquire(priority).then(resource => {
return fn(resource).then(
result => {
this.release(resource);
return result;
},
err => {
this.destroy(resource);
throw err;
}
);
});
}
(Pool.use的源码)
连接池准备好了我们将原有的生成海报的逻辑接入。
import Koa from 'koa'
import Router from '@koa/router'
import createPuppeteerPool from './pool.js'
const app = new Koa()
const router = new Router()
const pool = createPuppeteerPool({})
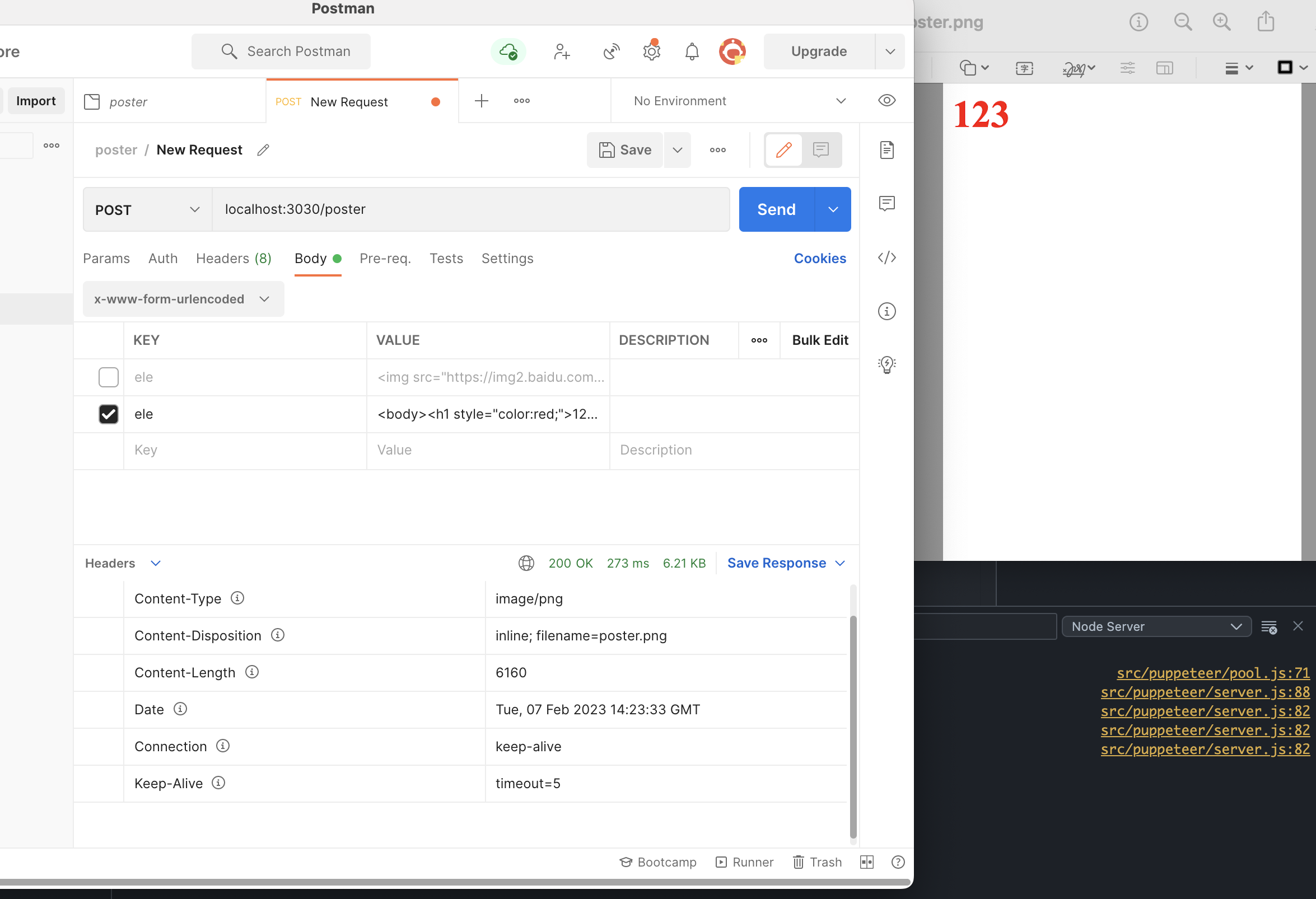
router.post('/poster', async (ctx, next) => {
const start = new Date().getTime()
let { body, query } = ctx.request
const {
width = 300,
height = 400,
ratio = 2,
type = 'png',
filename = 'poster',
waitUntil = 'domcontentloaded',
quality = 100,
omitBackground,
fullPage,
url,
useCache = 'true',
usePicoAutoJPG = 'true',
html
} = query
const {ele} = body
const result = await pool.use(async browser => {
const page = await browser.newPage();
let image;
try {
await page.setViewport({
width: Number(width),
height: Number(height),
deviceScaleFactor: Number(ratio)
});
await page.goto(url || `data:text/html,${ele}`, {
waitUntil: waitUntil.split(',')
});
image = await page.screenshot({
type: type === 'jpg' ? 'jpeg' : type,
quality: type === 'png' ? undefined : Number(quality),
omitBackground: omitBackground === 'true',
fullPage: fullPage === 'true'
});
} catch (error) {
throw error;
}
await page.close(); // 关闭页面
return image;
})
ctx.set('Content-Type', `image/${type}`);
ctx.set('Content-Disposition', `inline; filename=${filename}.${type}`);
ctx.body = result;
const end = new Date().getTime();
console.log(end - start + 'ms');
})
app.use(router.routes());
app.listen(3030, () => {
console.log('start: listening on 3030')
});
这里使用两种方式来进行渲染,静态 HTML 或者 URL,如果有能力甚至可以专门做一个海报模板平台,渲染时拉取模板进行渲染。
最后的实现效果如下