



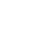



实现一个前端监控平台需要实现的部分主要有:
- 监控 SDK;
- 消息系统;
- 监控平台后端;
- 监控平台前端。
SDK 负责提供给业务前端收集错误日志、性能日志以及其他数据的能力;监控数据通过 SDK 发送给服务器,由专门的中间件负责日志消息的转发,这些中间件组成了消息系统;监控平台后端主要负责存储日志数据,为监控平台前端提供接口;监控平台前端负责数据的可视化展示以及业务应用的监控配置。
其大致的关系如下如所示
SDK
前端监控的 SDK 需要实现的功能是利用浏览器的 API 完成异常数据上报、性能数据上报、用户操作数据记录等。
处理 JS 的常规异常报错,还需要处理一些框架层面的异常,例如 Vue 和 React 等内部抛出的异常,这些框架一般都提供了错误拦截的接口。所以我们需要为不同的前端框架适配不同的 SDK。
错误捕获
JavaScript 中主要的错误类型有:
- Error:所有的错误类型的父类,一般是用户自定义异常;
- RangeError:越界,例如使用构造函数创建一个不合法长度的数组,new Array(Number.MAX_VALUE);
- ReferenceError:引用错误,最常见的是不存在的变量被引用;
- SyntaxError:语法错误,JavaScript 是解释型语言,只有在代码执行时才会检测出语法错误;
- TypeError:类型错误,常见于访问不存在的属性;
- URIError:encodeURI 和 decodeURI 参数不正确时抛出;
- EvalError:eval 执行的参数不正确时抛出异常
在浏览器中捕获这些异常可以使用 try-catch,但是不可能对每个代码块包裹 try-catch,我们可以通过事件来捕获异常。
onerror 句柄
onerror 的好处是可以同时捕获同步任务和异步任务,但是有个错误它无法捕获,unhandledrejection 也就是 Promise.reject抛出的异常。
另外,网络异常onerror 也无法捕获,例如图片地址错误等。
error 事件
监听 error 事件可以实现同 onerror 句柄一样的同步、异步异常捕获,同时,在捕获阶段可以监听到网络错误
window.addEventLinstener('error', (e) => {
console.log(e)
}, true)
两种方式都无法捕获unhandledrejection的异常,它需要额外的监听器来捕获,所以想要对所有的异常进行捕获我们最终需要使用的代码为
window.addEventLinstener('unhandledrejection', (e) => {
throw e
})
window.addEventLinstener('error', (e) => {
console.log(e)
}, true)
性能监控
除了对异常数据进行上报,SDK 还需要实现对页面性能数据进行上报,也就是我们再讨论性能优化的时候所对照的那几个指标

这些指标可以通过浏览器的 performance.timing 获取到

为了适应后期不同的需求变更,我们这里直接上传原始数据即可,在后台根据需求进行计算。
这几个属性的含义如下:
- connectEnd: 浏览器和服务器建立连接(完成握手和认证);
- connectStart: 开始向服务器发送 HTTP 请求;
- domComplete: 网页 DOM 结构生成;
- domContentLoadedEventEnd: 网页所有需要执行的脚本执行完成;
- domContentLoadedEventStart: domContentLoaded 事件触发;
- domInteractive: DOM 树构建完成,开始加载内嵌资源;
- domLoading: 开始解析 DOM 结构;
- domainLookupEnd: DNS 查询结束;
- domainLookupStart: DNS 查询开始;
- fetchStart: 发起 HTTP 请求读取文档;
- loadEventEnd: 网页 load 事件回调结束;
- loadEventStart: 网页 load 事件回调开始执行;
- navigationStart: 开始处理网页;
- redirectEnd: 重定向结束;
- redirectStart: 重定向开始;
- requestStart: 浏览器向服务器开始发送请求;
- responseEnd: 浏览器收到服务器最后一个字节;
- responseStart: 浏览器收到服务器第一个字节;
- unloadEventEnd: unload 事件结束运行。
- unloadEventStart: unload 事件开始执行。
这里大概说一下这几个时间能够进行的一些指标计算:
- DNS 查询耗时:domainLookupEnd - domainLookupStart;
- 请求响应耗时:responseStart - requestStart;
- DOM解析耗时:domInteractive - responseEnd;
- 内容传输耗时:responseEnd - responseStart;
- 资源加载耗时:loadEventStart - domContentLoadedEventEnd;
- 准备文档耗时:domContentLoadedEventEnd - fetchStart;
- 首次渲染耗时:responseEnd - fetchStart;
- 首次可交互事件:domInteractive - fetchStart;
- 页面加载完成耗时:loadEventStart - fetchStart;
- 首包耗时:responseStart - domainLookupStart;
- SSL 连接耗时:connectEnd - secureConnectionStart;
- TCP 连接耗时:connectEnd - connectStart。
有了这些指标我们就可以根据监控平台的性能数据看出网页中存在的性能问题,为前端性能优化提供数据层面的依据。
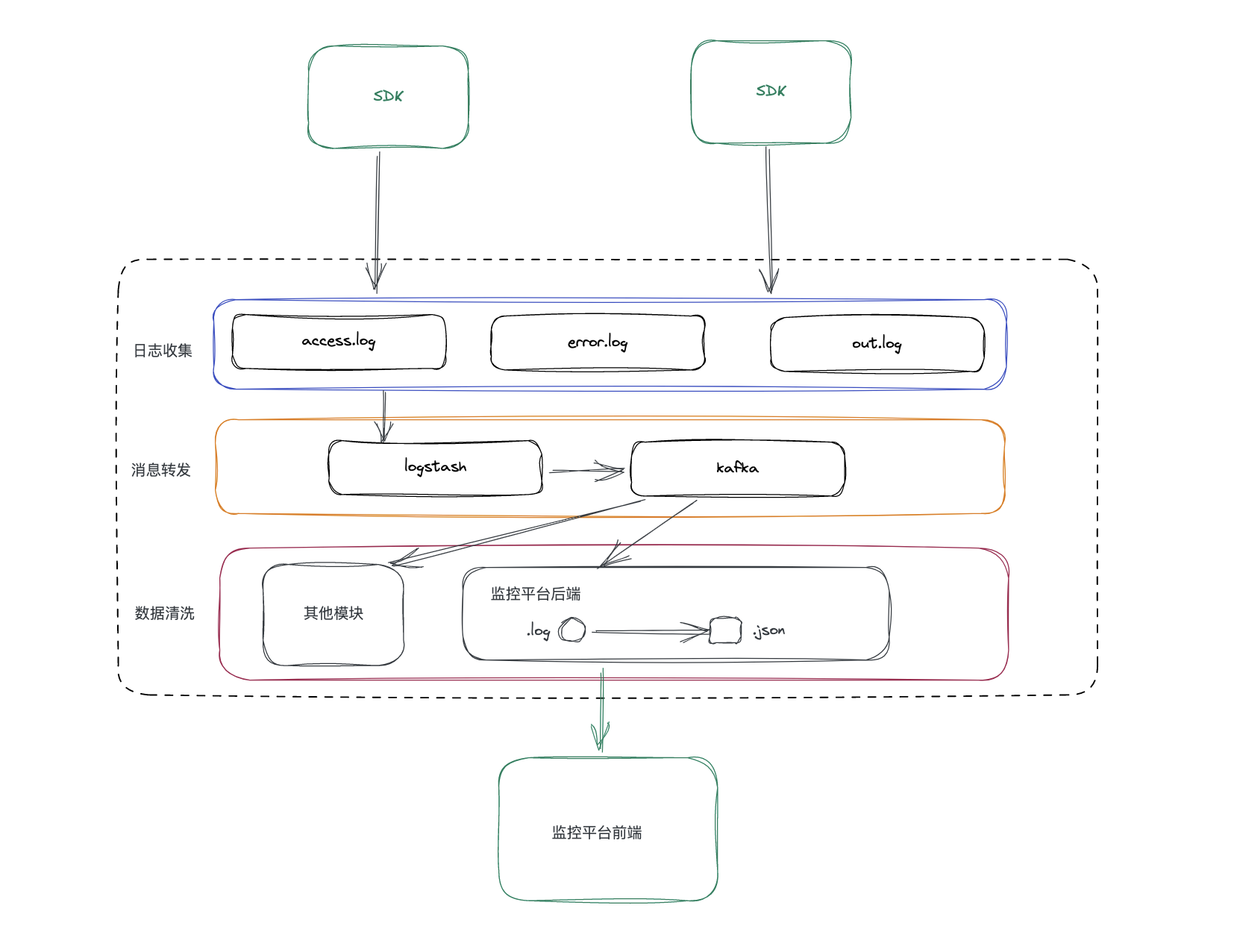
出了这些数据之外,我们还需要把用户的设备信息等环境信息进行上报,用于确定异常或者性能问题是否由用户设备问题引起。
用户的设备信息可以通过navigator.userAgent获取
主动上报
除了自动收集的异常和性能数据,我们还要开放 API 供开发者调用,某些情况下业务应用需要收集一些数据,这些东西并不是通用的,不能将其耦合在 SDK中,所以我们提供数据上传的接口让开发者自定义实现上报功能。
如果有其他的数据需要处理,根据公司的需求增加,前面三个是比较通用的情景。
数据上报
前面说完了几种需要上报数据的情况,下面来讲一下如何进行数据的上报。
一般来说监控平台和业务平台都在不同的服务器上,所以会存在跨域的问题,如果对在每个业务应用上都对监控平台进行跨域处理,也会浪费很多时间(主要是懒),所以我们的上报应该是无感的(指不需要进行额外的代码适配)。
所以我们不能使用 AJAX 的形式进行数据的上报,那么还有什么办法呢?
跨域是浏览器为了安全而设立的一种机制,但是图片、脚本等资源加载时不会受到限制,我们可以将要上报的数据放到资源加载的 URL 中。
最常见的就是使用一个1 像素的透明 GIF 来完成,那为什么不是 png,jpg 等其他格式呢?
首先,要使用透明的图片资源,这样几不会影响页面展示,而且透明图片不需要存储色彩空间数据,可以减小资源体积。那么支持透明格式的除了 GIF 还有 PNG 和 BMP,为什么不是两外两个?
这其实是由他们的图片存储结构决定的,三种格式中 1 像素大小的透明图片 GIF 的体积是最小的,大约是 35 字节。具体的图片存储结构自行百度吧。
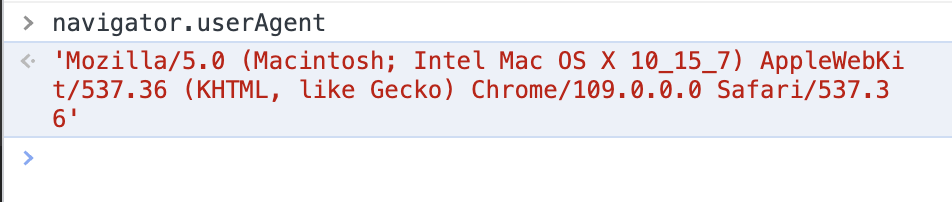
Nginx 中也提供了一个 empty_gif 功能
这样就可以返回一个最小体积的图片,然后我们通过 URL 来进行数据上报了
动态生成 Image 元素来上报数据
const timing = performance.timing;
const image = new Image();
image.src = "http://localhost/log-upload?timing=" + JSON.stringify(timing)
服务器收集到的日志如下
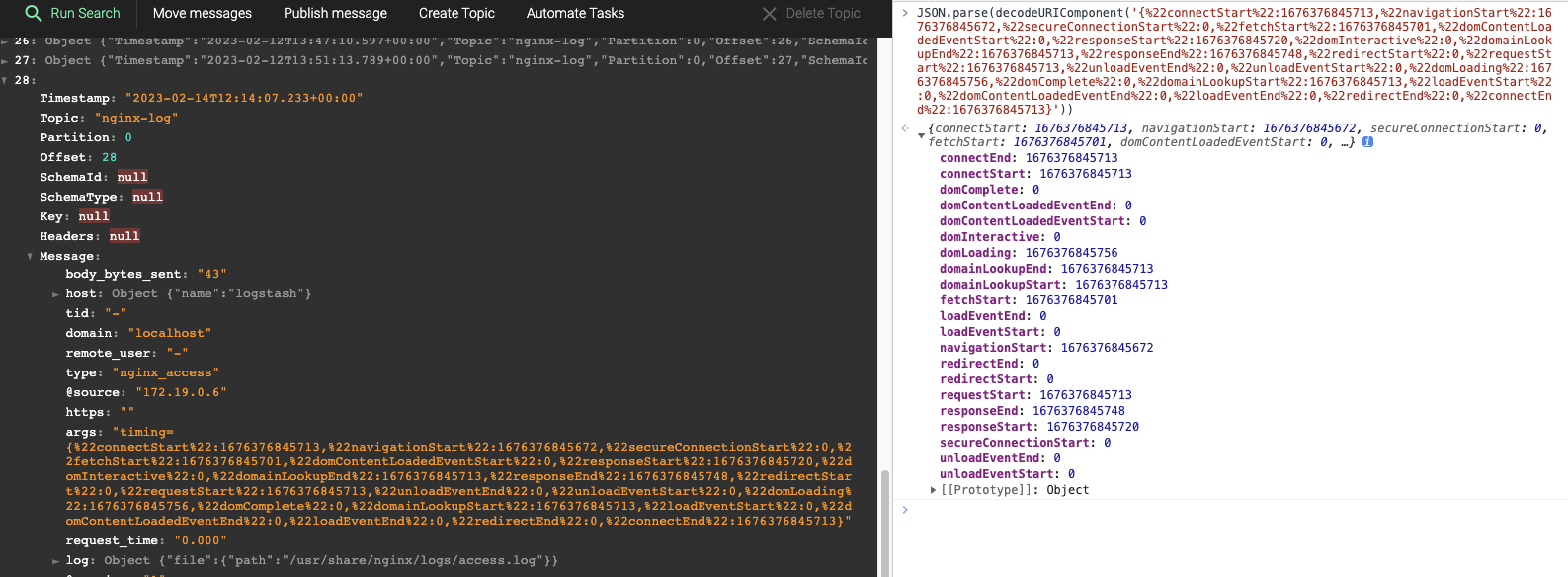
消息系统
上面一张图片就是将Nginx 日志转发到 Kafka 中的,我们要做的消息系统就是来完成这件事的。
由于日志平台接入了多个业务应用,上报的数据量可能比较大,所以我们的处理速度可能跟不上上报的速度,因此我们将数据接收的能力放到 Nginx 上,通过 Nginx 的访问日志来记录上报的监控数据。
然后通过 Logstash 来收集日志数据,并转发到 Kafka 中生成消息,最后由监控平台的服务端进行消费,进而降低网络 IO 对业务应用的影响,这个过程可以是多集群的。
Nginx
Nginx 就不用多说了,不论前端还是后端开发,应该都知道 Nginx 的大名,在静态资源服务器这一块拿捏得死死的,所以我们使用 Nginx 来监控数据的收集。
Nginx 的部署网上教程一堆,也可以容器化的方式进行部署,但是如果每一个中间件都采用容器化的方式部署,我们需要将一些文件通过卷挂载的方式放到容器中,这个后面我会放出一个完整的 docker-compose 文件。
我们在记录日志的时候,需要格式化为 JSON,以减轻后续解析日志的负担,这个使用 Nginx 自带的日志格式化功能即可。
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format logstash_json '{'
'"timestamp": "$time_iso8601",'
'"source": "$server_addr",'
'"hostname": "$hostname",'
'"ip":"$http_x_forwarded_for",'
'"client": "$remote_addr", '
'"scheme": "$scheme",'
'"domain":"$server_name",'
'"request":"$request_uri",'
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"request_length": "$request_length", '
'"request": "$request", '
'"request_method": "$request_method", '
'"http_content_type": "$http_content_type", '
'"upstream_addr" : "$upstream_addr" ,'
'"upstream_response_time": "$upstream_response_time", '
'"status": "$status", '
'"client_id": "$http_x_gw_client_id", '
'"http_referrer": "$http_referer", '
'"tid": "$http_tid", '
'"args": "$args",'
'"https": "$https",'
'"http_user_agent": "$http_user_agent"'
'}';
access_log /var/log/nginx/access.log logstash_json;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host:$server_port;
location /log-upload {
empty_gif;
}
}
}
Logstash
Logstash 是一个开源的数据处理管道,用于从不同的数据源收集数据,并将其进行转换、清理和存储到目标数据存储中。
Logstash 使用插件的形式支持多种数据源和目标数据存储,包括:
- 数据源:如文件、数据库、日志等
- 数据转换:如数据格式转换、正则表达式匹配、数据清洗等
- 数据存储:如 Elasticsearch、Kafka、Amazon S3 等
因此,Logstash 可以被用于实现各种数据收集、处理、存储场景,如日志收集、数据导入导出等。此外,Logstash 还可以与其他 ELK(Elasticsearch、Logstash、Kibana)技术结合,用于数据分析和可视化。
(以上内容来自 chatgpt)
最终使用这个 pipeline 进行收集即可
input {
file {
type => "nginx_access"
path => "/usr/share/nginx/logs/access.log"
codec => "json"
}
}
output {
kafka {
id => "logstash_kafka"
codec => "json"
topic_id => "nginx-log"
bootstrap_servers => "kafka:9092"
client_id => "logstash"
}
}
Kafka
Kafka 是一个重主题的 MQ 中间件,我之前记录过 Kafka 的一些内容,传送门
了解了这些东西之后就对消息系统有个大概的理解了,最后贴一份 docker-compose 部署脚本
version: '3.8'
networks:
app-tier:
driver: bridge
services:
zookeeper:
image: zookeeper:latest
container_name: zookeeper
hostname: zookeeper
networks:
- app-tier
ports:
- 2181:2181
environment:
ALLOW_ANONYMOUS_LOGIN: 'yes'
kafka:
image: wurstmeister/kafka:latest
container_name: kafka
hostname: kafka
networks:
- app-tier
ports:
- 9092:9092
environment:
KAFKA_BROKER_ID: 0
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_ADVERTISED_HOST_NAME: kafka
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
kafka-magic:
image: digitsy/kafka-magic:latest
container_name: kafka-magic
hostname: kafka-magic
networks:
- app-tier
ports:
- 8080:80
logstash:
image: docker.elastic.co/logstash/logstash:8.6.1
container_name: logstash
hostname: logstash
networks:
- app-tier
volumes:
- ./logstash/access.log:/usr/share/nginx/logs/access.log
- ./logstash/pipeline:/usr/share/logstash/pipeline/
nginx:
image: nginx:latest
container_name: nginx
hostname: nginx
networks:
- app-tier
volumes:
- ./logstash/nginx.conf:/etc/nginx/nginx.conf
- ./logstash/access.log:/var/log/nginx/access.log
ports:
- 80:80
注意几点:
- nginx 和 logstash 要挂载同一份日志文件,这样才能正确监听到文件变化(如果正常项目中有日志切割的话没法用这种方式);
- pipeline 脚本一定要挂在到指定目录,logstash 会自动检索目录下的 pipeline 脚本;
服务端
服务端主要负责解析一些数据,并给前端提供接口,其他的数据解析根据平台能力而定,但有一个能力比较通用,也很有意思——错误堆栈复原。
线上报错如果是原始错误堆栈的话我们很难定位错误位置,因为现代的前端代码都是经过打包压缩的代码,可读性几乎为0,所以我们需要根据 sourceMap 将错误堆栈复原(sourceMap 需要上传到平台才可以解析,这个也是监控平台需要提供的能力)。
错误堆栈的信息需要在后端解析(如果把 sourcemap 传到前端会很危险⚠️),这里我们可以扒一下 Sentry 的请求来验证一下。
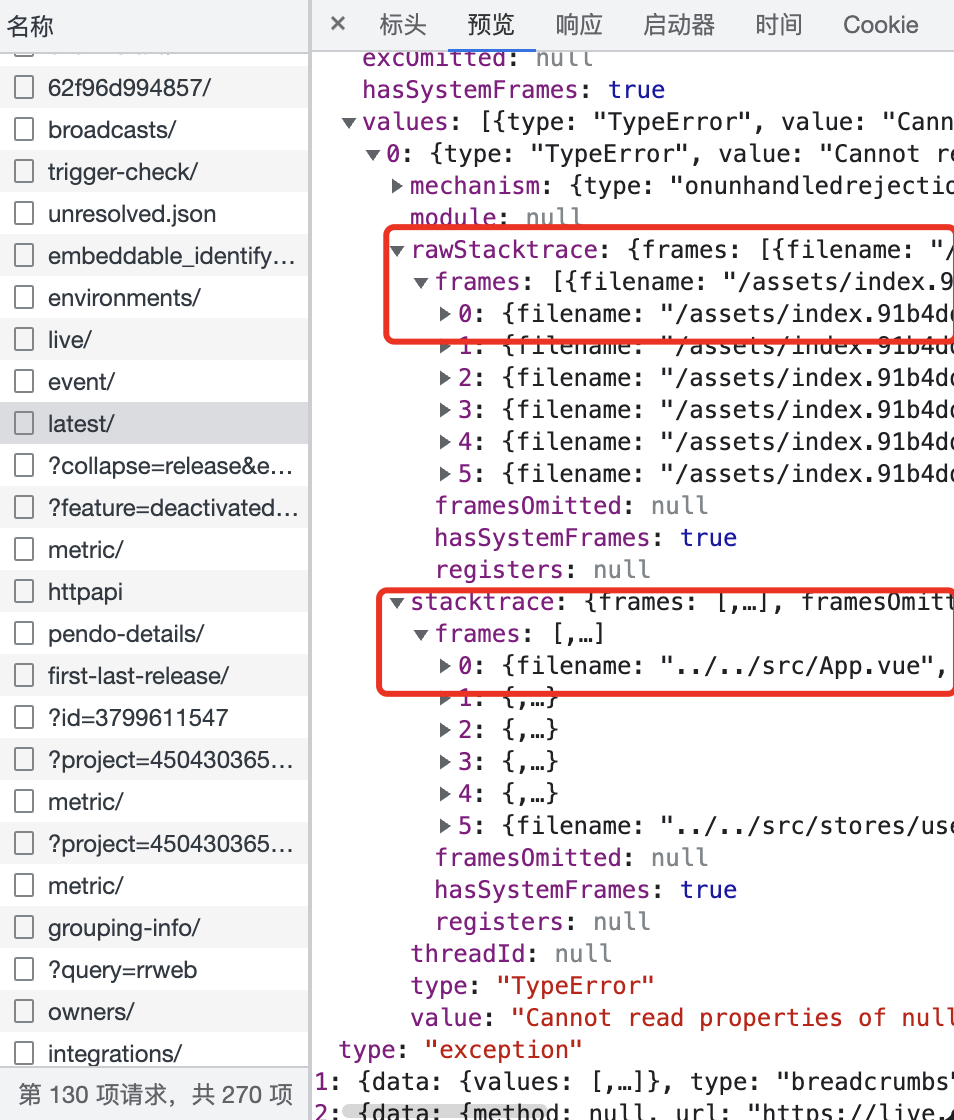
从 Sentry 的请求响应中可以看见,错误堆栈的还原是通过 API 获取的,图中rawStacktrace 即原始错误堆栈,stacktrace 是使用 sourceMap 还原的错误堆栈,这点从 filename 就可以看到,原始堆栈是打包后的静态文件,复原后的堆栈是源码路径。
这个过程主要依赖两个库:source-map 和 stacktracey,一个用于解析sourceMap 还原源码,另一个用于解析错误堆栈。
首先使用 stacktracey 解析错误堆栈,还是使用 Koa 开启个 server,看一下解析的错误堆栈是什么样子
router.get('/stack', async (ctx) => {
const { stack } = ctx.request.query
const tracey = new StackTracey(stack)
console.log(tracey);
ctx.body = 'hi'
})
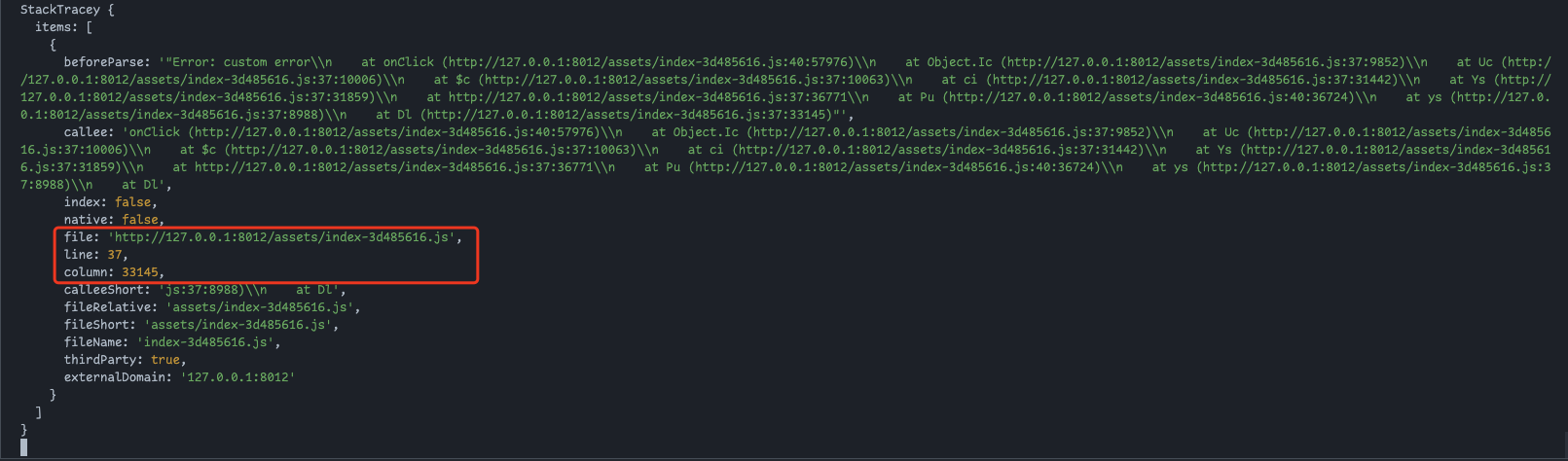
我们从错误堆栈中解析出了报错的文件以及代码的行列位置,其实就是异常堆栈中的编译后文件的文件名和行列号,我们甚至可以自己解析。
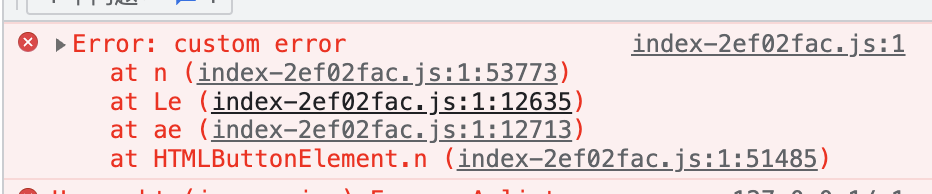
下一步我们将基于这些信息去寻找报错的源码,正常来说我们需要通过版本管理的方式来获取 sourceMap,这里只做还原的演示,所以就直接制作一个 sourcemap 本地加载了。
首先准备一个前端项目,我直接使用 vite 初始化一个 Vue 项目,在默认项目文件中加一个抛出异常的按钮事件。
<!--
* @Date: 2023-02-16 15:53:47
* @Author: 枫
* @LastEditors: 枫
* @description: description
* @LastEditTime: 2023-02-16 15:59:57
-->
<script setup lang="ts">
import { ref } from 'vue'
defineProps<{ msg: string }>()
const count = ref(0)
function throwError (){
throw new Error('custom error')
}
</script>
<template>
<h1>{{ msg }}</h1>
<button type="button" @click="count++">count is {{ count }}</button>
<button type="button" @click="throwError">Throw</button>
</template>
<style scoped>
.read-the-docs {
color: #888;
}
</style>
然后执行构建,将产生的map 文件移动到后端 server 目录下,并在前端 dist 目录中移除,使用 http-server 将 dist 下的静态文件暴露,访问地址,点击按钮触发异常,复制一下堆栈信息(正常应该是 SDK 捕获上报,这里就不搞那么麻烦了)。
完善一下 server 的解析逻辑
import { fileURLToPath } from 'node:url'
import { dirname, resolve } from 'node:path'
import { readFile } from 'node:fs/promises'
import sourceMap from 'source-map'
import StackTracey from 'stacktracey'
const __dirname = dirname(fileURLToPath(import.meta.url))
const sourcemapFile = await readFile(resolve(__dirname, 'index-2ef02fac.js.map'), 'utf8')
const rawSourceMap = JSON.parse(sourcemapFile)
const consumer = await new SourceMapConsumer(rawSourceMap);
router.post('/stack', async (ctx) => {
const { stack } = ctx.request.body
const tracey = new StackTracey(stack) // 解析异常堆栈, 数组结构
const sourceCodes = tracey.items.map(item => {
// 从源码中获取行列等信息
const { column, line, source, name } = consumer.originalPositionFor({
//编译产物的行列
line: item.line,
column: item.column,
});
// 异常所在的源文件代码
const sourceCode = consumer.sourceContentFor(source)
// 分割, 取出异常所在行的前后部分代码
const splitSourceCode = sourceCode.split('\n')
// 计算截取范围
let start = 0, end = splitSourceCode.length // 后面 slice end 还需+1,所以这里不-1
if (line - 5 > start) {
start = line - 5
}
if (line + 5 < end) {
end = line + 5
}
const rangeSourceCode = splitSourceCode
.slice(start, end)
.map((code, index) => [start + 1 + index, code])
return {
stacktrace: {
column,
line,
sourceCode: rangeSourceCode,
name,
path: source
},
rawStacktrace: stack
}
})
ctx.body = sourceCodes
})
逻辑都在注释中了,应该都能看懂。
此时访问一下这个接口,用我们上面复制下来的堆栈文本作为参数,拿到返回值,可以看到解析出对应的行号就是前面我们抛出异常的那一行。
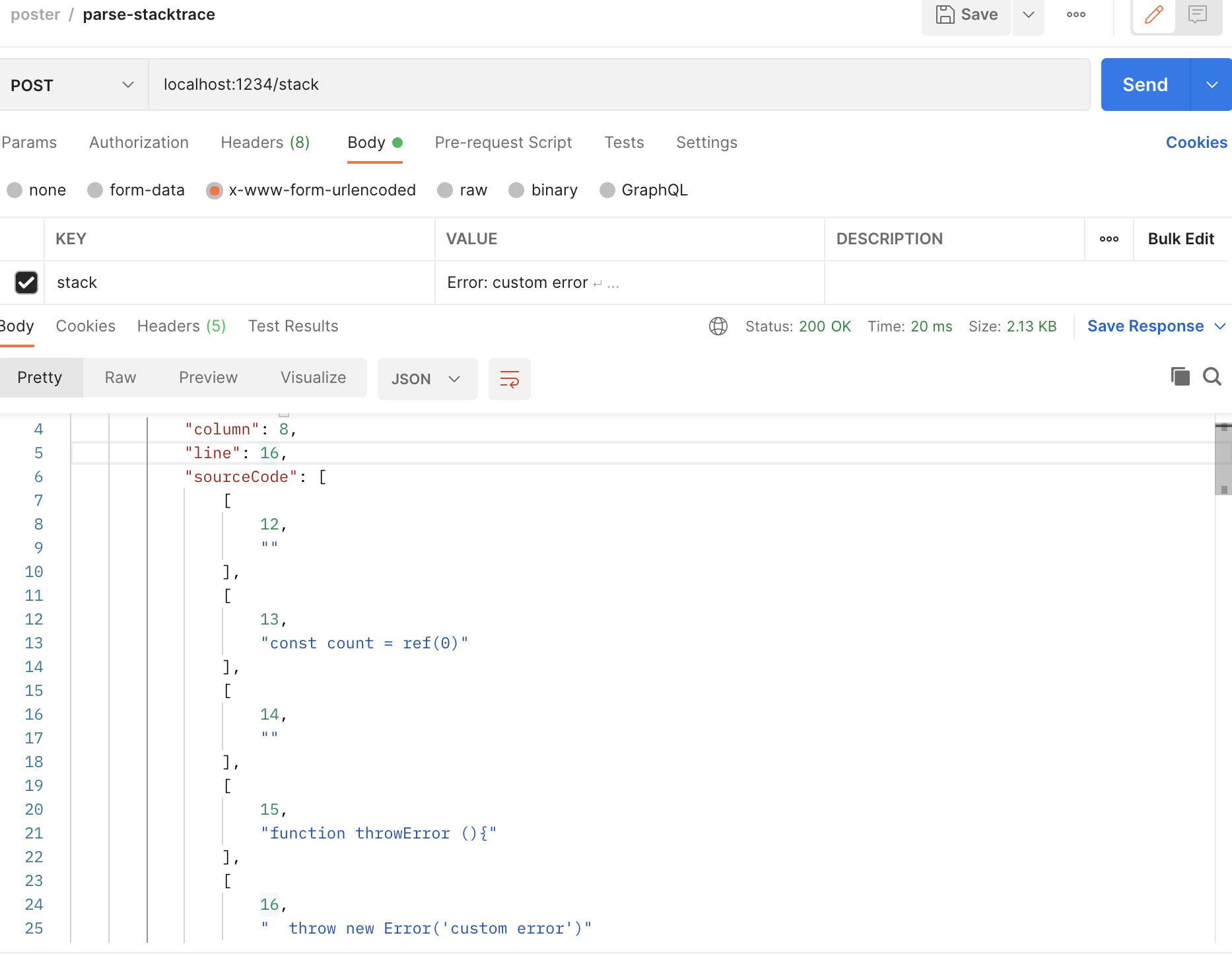
上面只是演示,真正的场景并不是请求时计算的,应该是异常上报时数据清洗的时候还原代码并保存到数据库中,页面获取异常数据时查询返回。
前端
前端的作用是对项目进行配置,以及收集数据的可视化展示。主要就是异常的告警、性能的分析、用户行为的记录。
主要是一些业务的需求,我们这里主要搞点有意思的东西。
异常代码定位
根据解析出来的源码进行展示(这里没啥技术含量,主要是比较有意思),主要是 CSS 的技巧。
利用了CSS 的 counter() 工具,配合 Vue3 的 CSS v-bind 可以快速实现效果。
<template>
<ul class="code">
<template v-for="code in data.sourceCode" :key="code[0]">
<li :class="{'active': code[0] === data.line}">
<pre>{{ code[1] }}</pre>
</li>
</template>
</ul>
</template>
<script setup lang="ts">
import { toRefs, defineProps, ref } from 'vue';
import { Stacktrace } from '../../typings/stack';
const props = defineProps<{ data: Stacktrace }>()
const { data } = toRefs(props)
const startLineNo = ref(data.value.sourceCode[0][0] as number - 1)
</script>
<style scoped>
.code {
text-align: left;
}
ul {
counter-reset: step;
counter-increment: step v-bind(startLineNo);
padding: 0;
}
li {
list-style: none;
position: relative;
margin: 4px 0;
padding-left: 50px;
}
.active {
background: rgb(43, 34, 51);
color: rgb(255, 255, 255);
}
li pre {
height: 23px;
margin: 0;
}
li::before {
content: counter(step);
counter-increment: step;
position: absolute;
left: 0;
top: 0;
display: block;
width: 30px;
text-align: right;
}
</style>
pre 标签主要是为了防止浏览器自动合并空格,使代码保持原有的缩进效果;
除了使用 pre 标签也可以通过 CSS 实现同样的效果:white-space: pre;
外层再配合 Element-Plus 的折叠面板,最终实现效果如下,可以直接查看报错的代码,快速定位错误,可以看到展示出来的代码和我们的原文件是一毛一样的。

具体的前端监控平台需要怎么实现还是看不同公司的具体需求,本文只是列举了一些常用的需求以及一些常用的解决方案。



