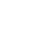



为什么需要消息队列
在知道为什么需要消息队列之前有必要知道什么是消息队列,那么,什么是消息队列呢?
“消息队列”是在消息的传输过程中保存消息的容器。
——百度百科《消息队列》
可能这句话比较模糊,不太能看懂。通俗来讲,消息队列本质上是一个队列,而队列中存放的是一个个消息。消息队列由 Broker(消息服务器,核心部分)、Producer(消息生产者)、Consumer(消息消费者)、Topic(主题)、Queue(队列)和Message(消息体)组成。
现在已经知道了什么是消息队列,那么为什么要用消息队列呢?
因为某些情况下同步处理会存在一些问题,例如:一系列的业务操作对系统开销较大,如果同步执行需要等待很长时间;同步执行过程中需要保证每个链路都执行成功,其中一环出现错误则会执行失败;又或者网络等不稳定因素会给用户带来不好的使用体验。
使用消息队列可以实现:解耦、异步、削峰。以最常见的电商订单为例,用户在支付之后系统需要进行的处理有:订单状态更新、用户积分发放、库存扣减、物流通知、短信(邮件)通知……如果等待全部执行完成完成再给用户反馈的话等待时间就太长了,用户体验非常不好,这时候就可以使用消息队列来将这个业务进行异步解耦。
在引入消息队列之前,我们的执行流程可能是这样的
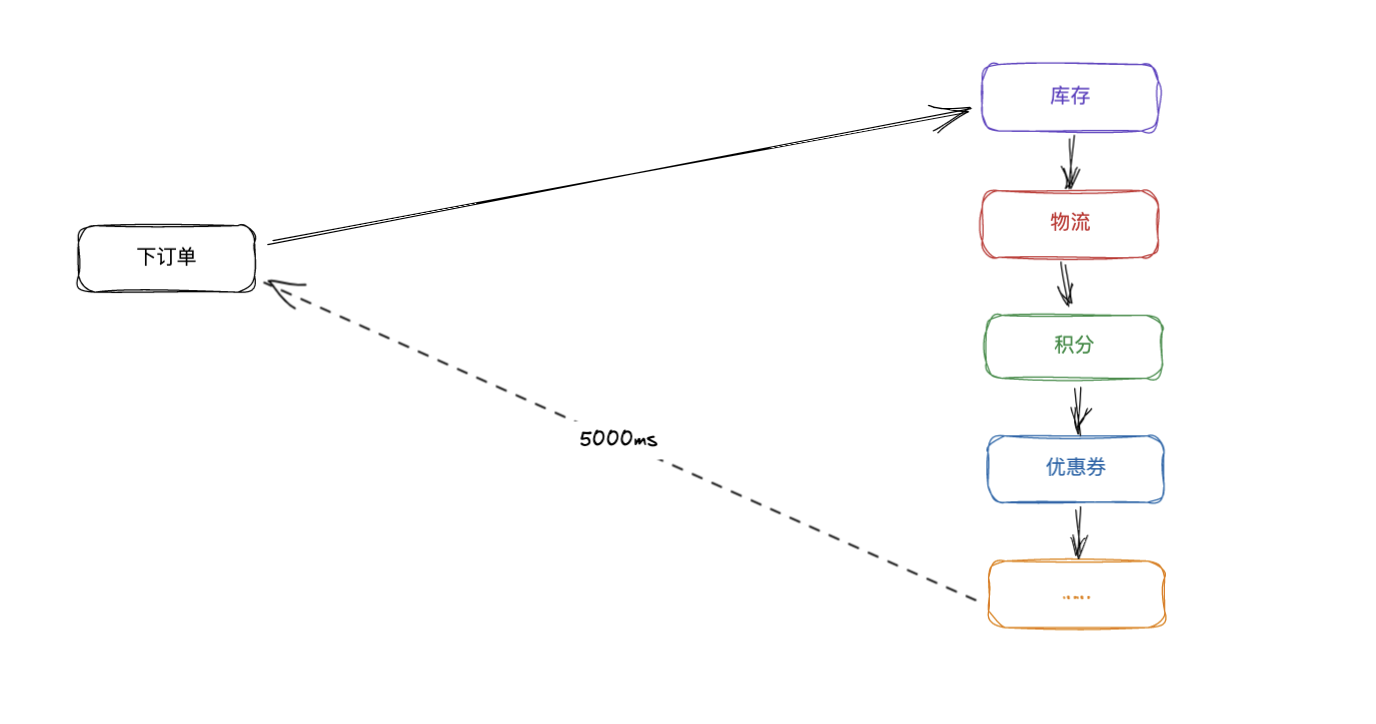
现在我们为使结果更快返回,我们加入消息队列
消息队列有两种流派,一种是重Topic,代表就是 kafka,另一种是轻Topic,代表是RabbitMQ。
先来看一下,kafka 中的基本概念
| 名称 | 解释 |
|---|---|
| Broker | 消息中间件处理节点,⼀个Kafka节点就是⼀个broker,⼀个或者多个Broker可以组成⼀个Kafka集群 |
| Topic | Kafka根据topic对消息进⾏归类,发布到Kafka集群的每条消息都需要指定⼀个topic |
| Producer | 消息⽣产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 每个Consumer属于⼀个特定的Consumer Group,⼀条消息可以被多个不同的Consumer Group消费,但是⼀个Consumer Group中只能有⼀个Consumer能够消费该消息 |
| Partition | 物理上的概念,⼀个topic可以分为多个partition,每个partition内部消息是有序的 |
安装 kafka及基本使用
物理机安装
在安装 kafka 之前需要做的准备工作如下:
- 安装 JDK
- 安装 zookeeper
- 下载 kafka 压缩包,官网下载地址
解压到/usr/local/kafka/路径,修改配置文件/usr/local/kafka/kafka-version(不同的包不一样)/config/server.properties
#broker.id属性在kafka集群中必须要是唯一
broker.id= 0
#kafka部署的机器ip和提供服务的端口号
listeners=PLAINTEXT://zkIP:9092
#kafka的消息存储文件
log.dir=/usr/local/data/kafka-logs
#kafka连接zookeeper的地址
zookeeper.connect= zkIP:2181
进入到 bin 目录下启动
$ ./kafka-server-start.sh -daemon../config/server.properties
可以通过命令行工具创建topic 来检测是否启动成功
$ ./kafka-topics.sh --create --zookeeper zkIP:2181 --replication-factor 1 --partitions 1 --topic test
# Created topic test.
容器部署
2024-02-22 更新,部署简化,可以不再使用zookeeper
docker run -d --name kafka -p 9092:9092 --hostname kafka \ -e KAFKA_CFG_NODE_ID=0 \ -e KAFKA_CFG_PROCESS_ROLES=controller,broker \ -e KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 \ -e KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT \ -e KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093 \ -e KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER \ bitnami/kafka:latest
或者使用 docker 进行更为简便的容器化部署
# 建立网络组
$ docker network create app-tier --driver bridge
# 拉取 kafka 和 zookeeper 的镜像
$ docker pull zookeeper:latest wurstmeister/kafka:latest
# 启动 zookeeper
$ docker run --network app-tier -d --name zookeeper -p 2181:2181 zookeeper:latest
# 启动 kafka
docker run -d --name kafka \
--network app-tier \
-p 9092:9092 \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
wurstmeister/kafka:latest
使用可视化界面来检测是否启动成功
$ docker run -d --name kafka-magic --network app-tier -p 8080:80 digitsy/kafka-magic:latest
打开localhost:8080页面,新建连接,在填写 kafka 地址的时候如果是本地 docker 非 host 模式部署的 kafka 地址不能直接填入 localhost 本机地址,需要填入容器名
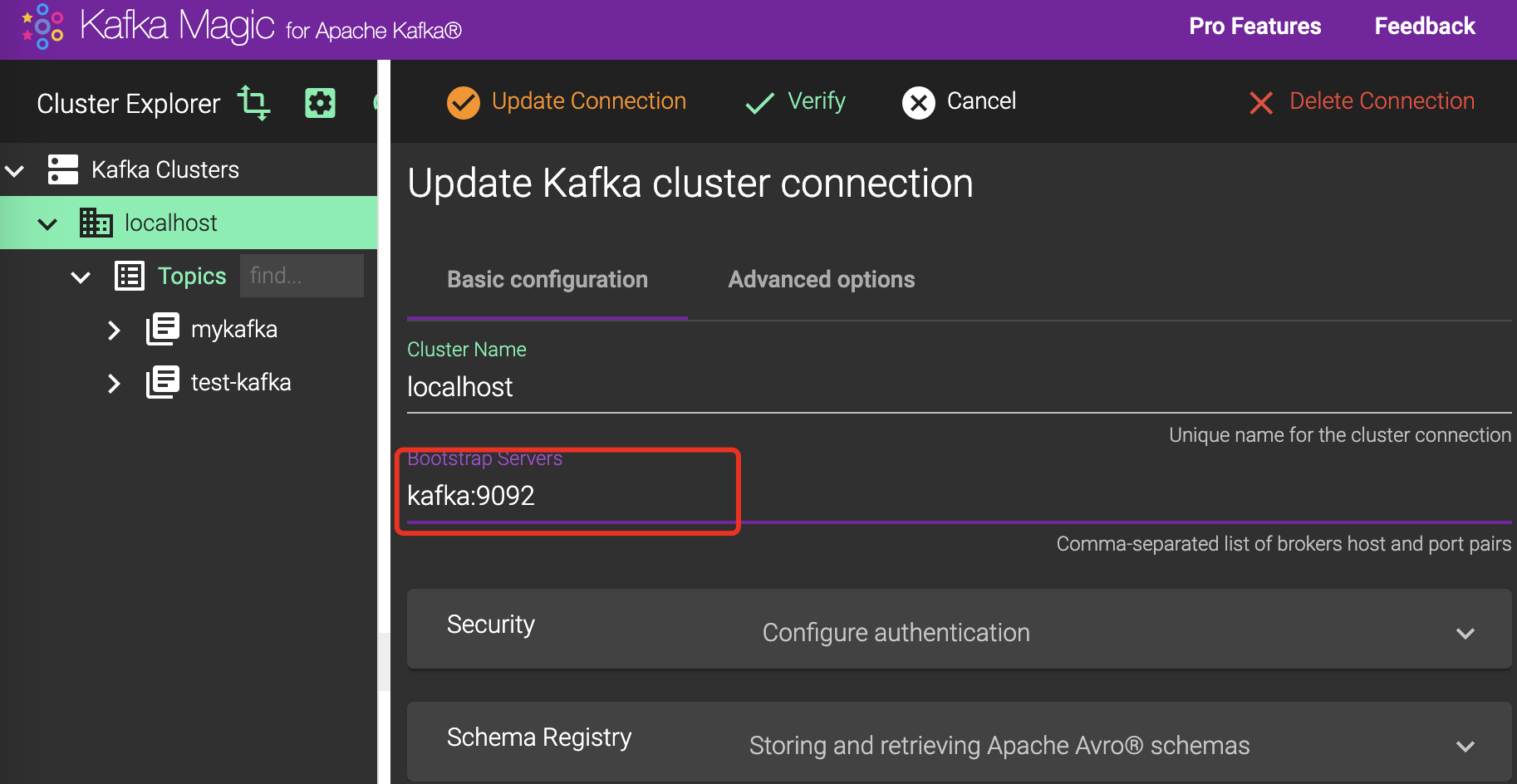
为了方便我已经将三个镜像编排在了一起,可以直接使用docker-compose up -d来运行
version: '3.8'
networks:
app-tier:
driver: bridge
services:
zookeeper:
image: zookeeper:latest
container_name: zookeeper
hostname: zookeeper
networks:
- app-tier
ports:
- 2181:2181
environment:
ALLOW_ANONYMOUS_LOGIN: 'yes'
kafka:
image: wurstmeister/kafka:latest
container_name: kafka
hostname: kafka
networks:
- app-tier
ports:
- 9092:9092
environment:
KAFKA_BROKER_ID: 0
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_ADVERTISED_HOST_NAME: kafka
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
kafka-magic:
image: digitsy/kafka-magic:latest
container_name: kafka-magic
hostname: kafka-magic
networks:
- app-tier
ports:
- 8080:80
如果使用容器部署,无法在宿主机通过 localhost:9092来访问 kafka 容器,需要在宿主机添加 hosts:kafka(容器名,也是环境变量KAFKA_ADVERTISED_LISTENERS设置的 host 名) 127.0.0.1 ;
即:KAFKA_ADVERTISED_LISTENERS的值必须和访问地址一致!
命令行工具
消息
如果使用 docker 安装,可以进入容器内部来使用命令行工具,具体路径如下

kafka 提供的常用命令行工具如下
# 创建 topic
$ ./kafka-topics.sh --create --zookeeper zkIP:2181 --replication-factor 1 --partitions 1 --topic topicName
# 查看 topic 列表
$ ./kafka-topics.sh --list --zookeeper zkIP:2181
# 把消息发送给 borker 的某个 topic,可以读取文件,也可以从命令行输入
$ ./kafka-console-producer.sh --broker-list kafkaIP:9092 --topic topicName
# 消费消息
## 从最后一条消息偏移量为+1开始消费
$ ./kafka-console-consumer.sh --bootstrap-server kafkaIP:9092 --topic topicName
## 从头开始消费
$ ./kafka-console-consumer.sh --bootstrap-server kafkaIP:9092 --from-beginning --topic topicName
zkIP:zookeeper 的 IP 地址
kafkaIP:kafka 的 IP 地址
topicName:topic 的名称
生产者消费者效果如下,如果是逐条读取不会读取之前的消息,只会接受最新产生的消息,如果从头开始消费可以一次性读取之前产生的消息。

kafka 的消息有以下特点。
- 消息会被存储
- 消息是顺序存储
- 消息通过偏移量描述消息的有序性
- 消费时可以指明偏移量进行消费
单播和多播
- 单播消息:一个消费组里,只会有一个消费者能消费到某一个topic中的消息。
- 多播消息:在不同的消费组订阅同一个 topic,那么不同的消费组中只有一个消费者能收到消息。
即控制单播多播的方式就是消费组,通过操作消费者所在消费组的方法来实现多播和单播。
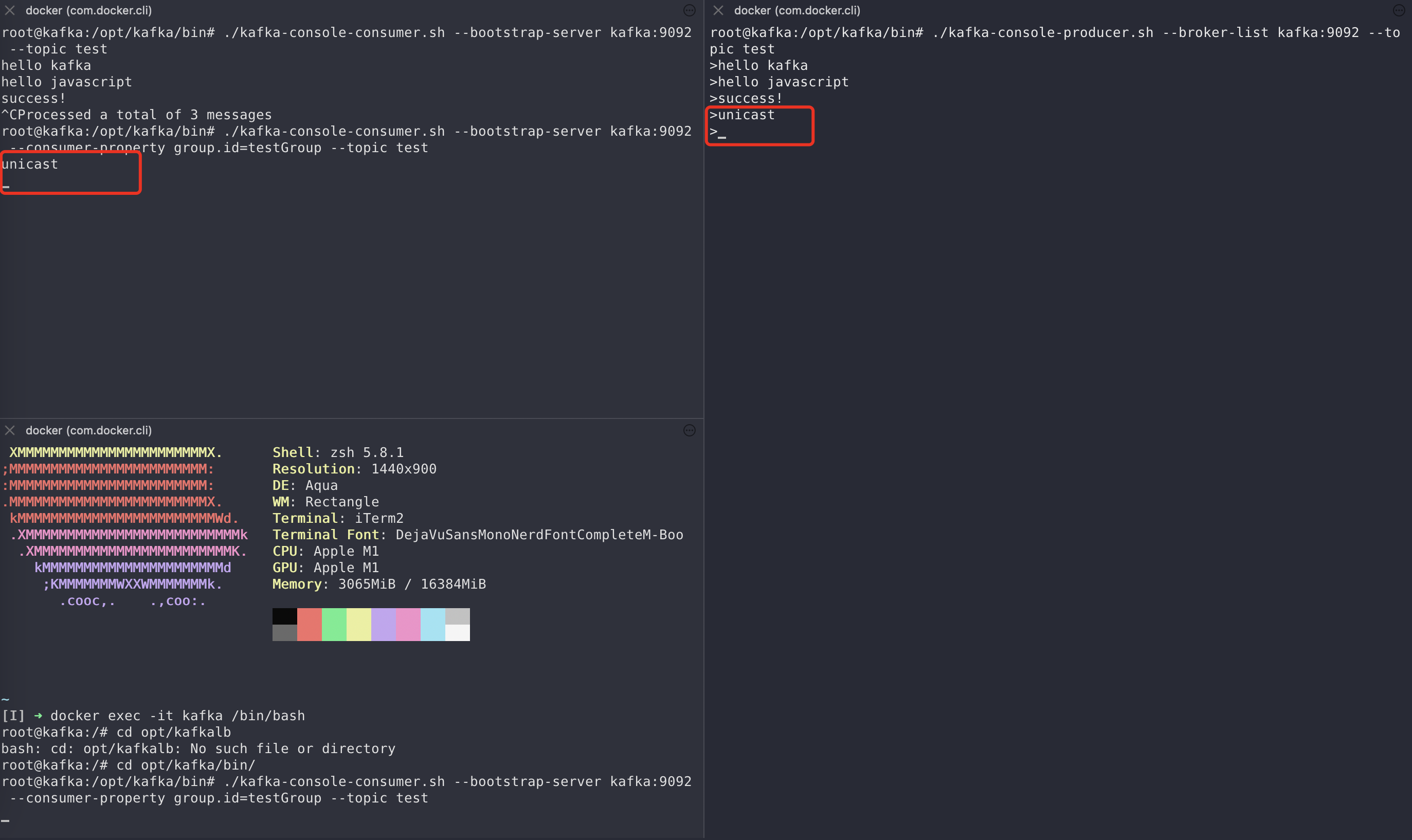
$ ./kafka-console-consumer.sh --bootstrap-server kafka:9092 --consumer-property group.id=testGroup --topic test
单播时如下所示,testGroup 消费组里面只有一个消费者能够收到消息。
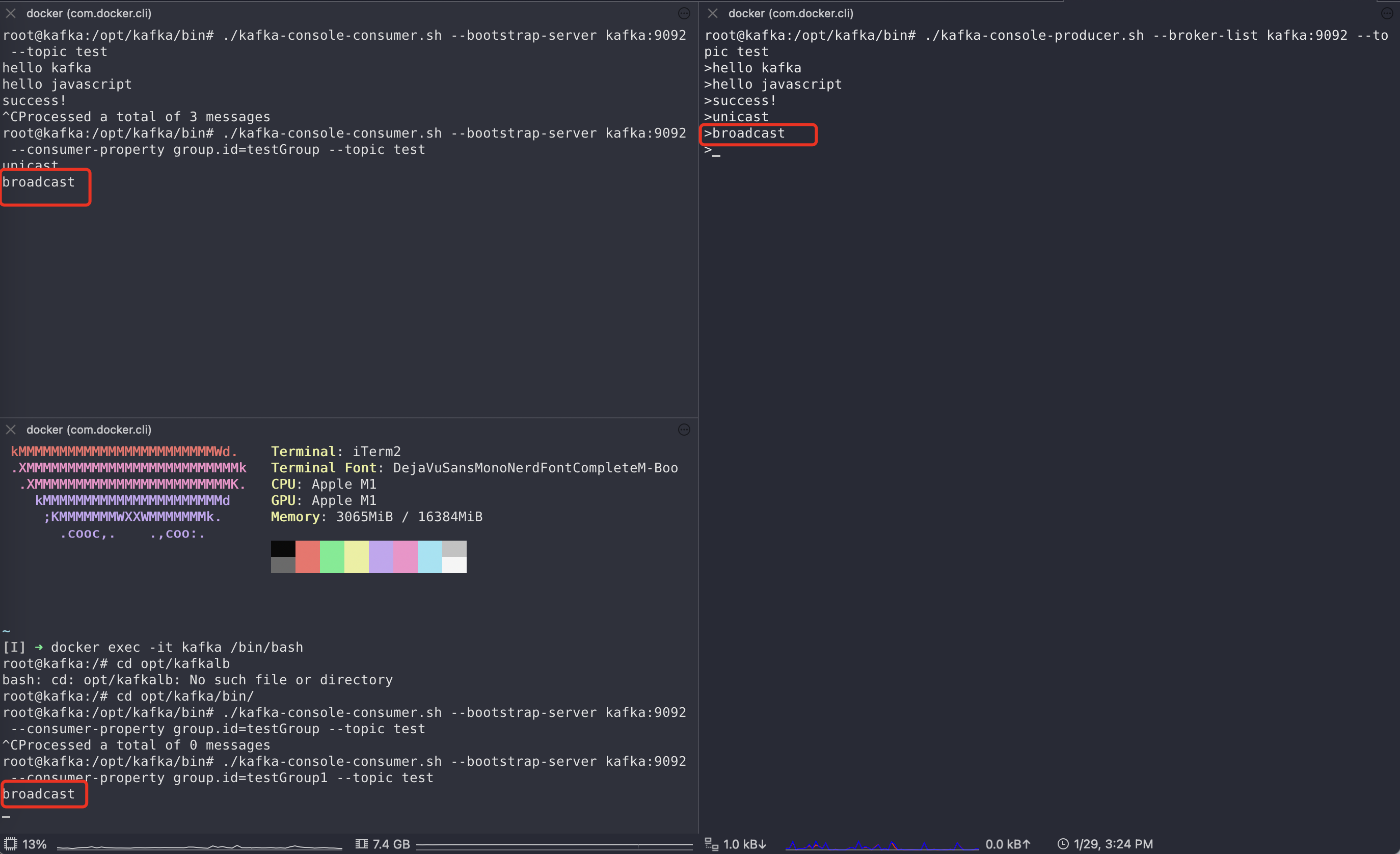
多播时两个消费者都可以收到消息(这里只开启了两个不同消费组的消费者)
可以使用命令查看消费组的信息
# 查看所有的消费组列表
$ ./kafka-consumer-groups.sh --bootstrap-server kafka:9092 --list
# testGroup1
# testGroup
# 可以查看具体某个消费组的详细信息
$ ./kafka-consumer-groups.sh --bootstrap-server kafka:9092 --describe --group testGroup
# GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
# testGroup test 0 7 8 1 consumer-testGroup-1-3ef8c0c1-bbcd-4353-af20-a87000c0aec8 /172.19.0.2 consumer-testGroup-1
其中消费组详细信息中的部分字段含义如下
- Currennt-offset: 当前消费组的已消费偏移量
- Log-end-offset: 主题对应分区消息的结束偏移量(HW)
- Lag: 当前消费组未消费的消息数
kafka 的基础使用基本就是以上的内容,如果不需要深入学习原理已经足够日常使用了。
在 nodejs 中使用 kafka
在 npm 中有 kafkajs 的依赖,其提供了生产者和消费者的client,让我们可以通过代码来控制消息的读写。
我非常喜欢的框架 MidwayJS 也提供了 kafka 的接入,其底层实现也是使用了 kafkajs 这个包,下面我们用 midway 的方式来体验一下在代码中接入 kafka。
在开始介入之前我们在配置文件中添加 kafka 的一些配置,方便我们管理,提高代码的可维护性。
import { MidwayConfig } from '@midwayjs/core';
export default {
// use for cookie sign key, should change to your own and keep security
keys: '1674981835754_4745',
koa: {
port: 7002,
},
kafka: {
kafkaConfig: {
clientId: 'kafka-client',
brokers: [process.env.KAFKA_URL || 'kafka:9092'],
},
consumerConfig: {
groupId: 'testGroup',
},
},
} as MidwayConfig;
这里的 kafka:9092 我在本地 hosts 文件中添加了解析到 127.0.0.1,因为是基于docker 容器进行部署的。
首先是消费者,Midway 为消费者封装了一系列装饰器,让我们可以非常方便的连接 kafka 消费者 client。在 src 目录下创建 consumer 目录,新建 log.consumer.ts 文件用于编写消费者代码。
import {
Consumer,
Inject,
KafkaListener,
MSListenerType,
Provide,
} from '@midwayjs/decorator';
import { IMidwayKafkaContext } from '@midwayjs/kafka';
import { KafkaMessage } from 'kafkajs';
@Provide()
@Consumer(MSListenerType.KAFKA)
export class UserConsumer {
@Inject()
ctx: IMidwayKafkaContext;
@Inject()
logger;
@KafkaListener('test')
async gotData(message: KafkaMessage) {
this.logger.info(
'test output =>',
message.offset + ' ' + message.key + ' ' + message.value.toString('utf8')
);
}
}
使用MSListenerType.KAFKA 表示消费者的类型是 kafka,KafkaListener装饰器传入的参数就是 kafka 中的主题。每一条 message 中的value 是一个 buffer 类型,使用时需要转为字符串。
Midway 并没有为生产者做太多的封装,所以这里需要使用 kafkajs 的 SDK 来进行生产者客户端操作。我们将生产者当做一个 service 引入然后调用方法即可。
import {
Autoload,
Config,
Destroy,
Init,
Inject,
Provide,
Scope,
ScopeEnum,
} from '@midwayjs/decorator';
import { Kafka, ProducerRecord } from 'kafkajs';
@Autoload()
@Provide()
@Scope(ScopeEnum.Singleton)
export class KafkaService {
@Config('kafka')
kafkaConfigMap: any;
private connection;
private producer;
@Inject()
logger;
@Init()
async connect() {
const {
brokers,
clientId,
producerConfig = {},
} = this.kafkaConfigMap.kafkaConfig;
const client = new Kafka({
clientId: clientId,
brokers: brokers,
});
this.producer = client.producer(producerConfig);
this.connection = await this.producer.connect();
}
// 发送消息
public async send(producerRecord: ProducerRecord) {
return this.producer.send(producerRecord);
}
@Destroy()
async close() {
await this.connection.close();
}
}
声明这个 service 是一个单例,并且添加 Autoload 注解,所以这个 service 会在程序运行时自动初始化,并且只会有这一个实例。
最后只需要在 controller 中调用这个 service 即可。
import { Inject, Controller, Get } from '@midwayjs/decorator';
import { KafkaService } from '../service/kafka.service';
@Controller('/api')
export class APIController {
@Inject()
kafkaService: KafkaService;
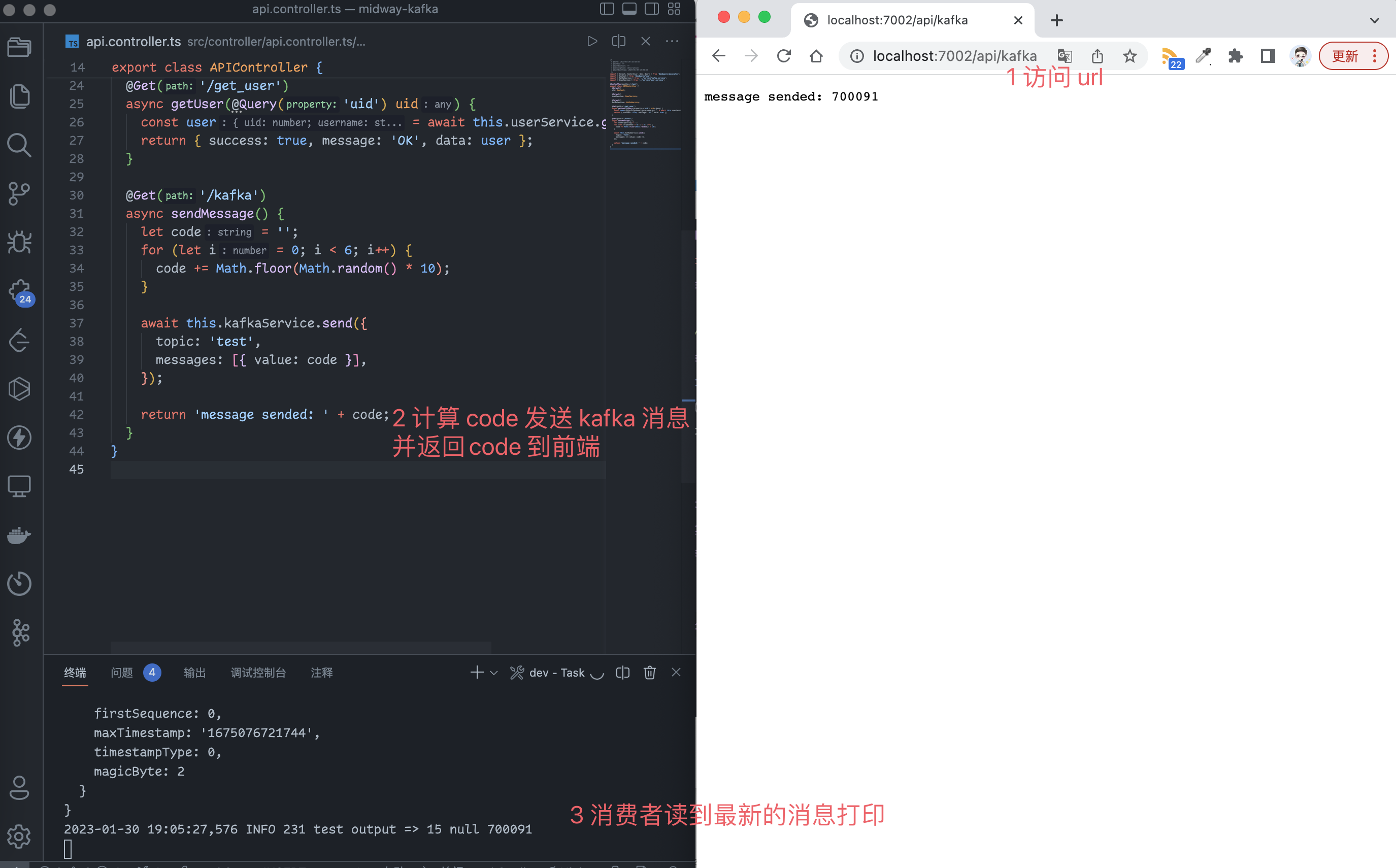
@Get('/kafka')
async sendMessage() {
let code = '';
for (let i = 0; i < 6; i++) {
code += Math.floor(Math.random() * 10);
}
await this.kafkaService.send({
topic: 'test',
messages: [{ value: code }],
});
return 'message sended: ' + code;
}
}
最终实现的效果如下