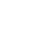



了解Babel
Babel是一个用于转换JavaScript代码的工具,支持将新版JS编写的代码转换成旧版JS代码,从而让新版的JS可以在旧版的浏览器或者环境中运行。Babel的整体架构可以分为三个主要的模块:
- Parser:负责解析输入的代码,并且将代码转化为抽象语法树(AST)的形式。这个模块会检查代码是否符合语法规范,并且将代码中的各种元素(比如变量、函数、运算符等)解析成AST节点的形式。
- Transformer:负责遍历和修改生成的AST。在这个模块中,Babel提供了很多插件,每个插件可以对AST进行不同的操作,比如添加、修改或者删除节点。用户可以自由选择需要的插件,以便实现对代码的特定转换。
- Generator:负责将经过转换后的AST转化为目标代码。这个模块会将AST节点按照一定的顺序输出成字符串形式的代码。在这个过程中,用户可以指定不同的输出格式(比如ES5、ES6等)。
除了以上三个模块,Babel还有一些辅助模块,比如负责文件读写的模块、处理命令行参数的模块等。这些模块共同构成了Babel的整体架构,为用户提供了一个强大而灵活的代码转换工具。
除了这三个核心模块,Babel还提供了其他常用的的工具包:
- @babel/code-frame:代码块,常用于在控制台打印代码块报错;
- @babel/types:AST类型包,常用于在transform阶段进行节点类型操作;
- @babel/template:使用代码模板生成AST,可以减少操作AST的繁琐步骤。
常用 Babel API
下面我们会从三个阶段来熟悉Babel的常用API
parse
parse阶段主要使用的是@babel/parser,它提供了两个函数,parse和parseExpression,二者的区别是parse会解析整个程序而parseExpression只会解析表达式。
babelParser.parse(code, [options])
babelParser.parseExpression(code, [options])
code 即源代码,options接受一个配置对象,常用的配置属性有:
- plugins:插件,指定解析的语法,例如tsx文件需要指定
typescript和jsx; - sourceType:模块语法,module(ESM)、script(不解析ESM)、unambiguous (根据有无 import 和 export判断是moduel还是script);
- strictMode:是否严格模式;
- startLine:起始行;
- errorRecovery:出错时是否继续;
- tokens:是否保留 token 信息;
- ranges:是否添加 ranges 属性;
- 以及一系列是否允许某语法

transform
transform阶段使用的是@babel/traverse,它提供了traverse函数用于操作AST,另外在这个阶段中可以用到@babel/template和@babel/types来提供辅助。
traverse(parent, options)
parent即需要进行遍历的AST节点,options是指定的visitor对象,babel会在遍历parent的时候调用对应的visitor方法。
options的形式如下
const intlCall = template.expression(`f({id: %%id%%, dm: %%dm%%})`);
traverse.default(ast, {
TemplateLiteral(path, state) { // 遍历时可以通过state在不同的节点之间传递数据。
const quasis = path.node.quasis;
for (const index in quasis) {
if (quasis[index].value.raw === "replace") {
quasis[index] = intlCall({
id: "replace",
dm: "default message"
});
}
}
path.skip();
}
})
// 字符串模板会将占位符放在expressions中,固定文本放在quasis中
通过template工具可以快速生成指定代码的AST,并且可以通过两个百分号进行包裹来传递变量,如上面代码所示。这可以帮助我们减少手动生成AST节点的繁琐操作。
- template.ast 返回的是整个 AST;
- template.program 返回的是 Program 根节点;
- template.expression 返回创建的 expression 的 AST;
- template.statements 返回创建的 statems 数组的 AST。
在options中,我们想要处理什么样的节点就讲节点的类型作为方法名,然后对path进行处理,path常用的属性和方法有:
- path.node 指向当前 AST 节点
- path.parent 指向父级 AST 节点
- path.getSibling、path.getNextSibling、path.getPrevSibling 获取兄弟节点
- path.find 从当前节点向上查找节点
- path.get、path.set 获取 / 设置属性的 path
- path.isXxx 判断当前节点是不是 xx 类型
- path.assertXxx 判断当前节点是不是 xx 类型,不是则抛出异常
- path.insertBefore、path.insertAfter 插入节点
- path.replaceWith、path.replaceWithMultiple、replaceWithSourceString 替换节点
- path.remove 删除节点
- path.skip 跳过当前节点的子节点的遍历
- path.stop 结束后续遍历
如果有多个类型有同一个处理逻辑,可以通过管道符进行连接,例如StringLiteral|NumberLiteral(path) {}
除了使用template来生成AST,我们前面也提到了可以通过types来手动创建AST节点,如下所示,我们在遍历的过程中通过types生成新节点来进行节点的替换或者判断节点的类型。
import t from '@babel/types'
traverse.default(ast, {
ConditionalExpression(path) {
const { test, consequent, alternate } = path.node;
const ifStatement = t.ifStatement(
test,
t.blockStatement([t.returnStatement(consequent)]),
t.blockStatement([t.returnStatement(alternate)])
);
path.replaceWith(ifStatement);
}
})
上面的代码中我们将三元表达式节点替换为了ifelse的形式,除了生成节点之外,types还可以用于判断节点类型,通过isXXX和assertXXX来判断节点是否是否个类型(断言会抛出异常),例如isIfStatement可以判断节点是否是if语句。
更多类型可以在@babel/types文档查看
generate
generate阶段主要使用@babel/generator包来完成对修改后的AST进行代码转换,它提供了generate函数来进行代码生成。
generate(ast, options, code)
ast 即解析后或者转换后的ast节点,options用于控制在生成代码时的一些细节,例如comments控制是否包含注释、sourceMaps控制是否生成sourcemap等,详情可见babel文档,code在多个文件编译时起作用,要传入文件名对应的源码。
export function generateCode(ast: Node) {
return generate.default(ast, {
sourceMaps: true,
comments: false
})
}
插件和preset
babel 的插件配置方式有两种:
webpack 配置 loader 时绑定插件
module: { rules: [ { test: /\.js$/, exclude: /node_modules/, use: { loader: 'babel-loader', options: { plugins: ['babel-plugin-xxx'] } } } ] }通过 babel 配置文件添加插件
export default { plugins: [['babel-plugin-xxx', {/*options*/}]] }
babel 插件是可以传参数的,可以在配置时将插件放在数组里面,第二个元素就会作为参数传到第一个参数声明的插件中。
插件名称可以填写路径来指定文件。
插件
插件有两种格式,一种是返回对象的函数,函数的形式主要用于接收配置传入的参数;另一种是对象。
一个函数插件格式如下
/**
* @param {import('@babel/helper-plugin-utils').BabelAPI} api
*/
export default function (api, options, dirname) {
const { template, types } = api;
const { innerLog } = options;
return {
name: 'babel-plugin-inner-log',
visitor: {
CallExpression(path) {
if (path.node.callee.type === "MemberExpression" &&
path.node.callee.object.name === "console" &&
path.node.callee.property.name === "log"
) {
path.node.arguments.push(types.stringLiteral(innerLog));
}
}
}
}
}
返回的对象有以下常用属性
- name 指定插件名称;
- inherits 指定继承某个插件,和当前插件的 options 合并;
- visitor 指定 traverse 时调用的函数;
- pre 和 post 分别在遍历前后调用,可以做一些插件调用前后的逻辑;
- manipulateOptions 用于修改 options,是在插件里面修改配置的方式;
对象形式的插件只是去掉了函数的包裹,不能够进行传参,其他的同上面一样。
preset
一个插件应该只处理一件事,但是这样在配置的时候会非常繁琐,所以有了preset,一个preset即一个plugin的集合,可以通过引入一个preset来引入一个系列的插件。
一个preset就是一个对象,对象有plugins和presets两个属性,分别用于配置插件和preset。
plugin和preset的执行顺序有所不同,plugin是从前往后,preset是从后向前。
实战加深理解
下面的内容我们将通过几个例子来加深对Babel的理解。
国际化自动提取中文并翻译
现在有这么一个jsx文件
/*
* @Date: 2023-05-29 20:22:28
* @Author: 枫
* @LastEditors: 枫
* @description: description
* @LastEditTime: 2023-06-01 21:13:47
*/
import React, { useState } from 'react'
import Header from './Header'
export default function BillList() {
const [count, setCount] = useState(0)
const clickHandler = () => {
setCount(count + 1)
}
return (
<div>
<Header title="账单列表" />
{count}
<button onClick={clickHandler}>查看账单</button>
</div>
)
}
首先要列举一下我们需要提取的节点类型有哪些:
- StringLiteral
- TemplateLiteral(比较复杂)
- JSXText
首先进行最简单的字符串字面量的提取,这里需要判断一下父节点是否为jsx的标签属性以及是否有jsx表达式容器;然后是jsx文本,直接提取并嵌套jsx表达式容器即可。
export function intlTransform(ast) {
const intlCall = template.expression(`f({id: %%id%%, dm: %%dm%%})`);
const intlCallWithParam = template.expression(`f({id: %%id%%, dm: %%dm%%}, %%params%%)`);
let id = 0;
const chineseReg = /^(?:[\u3400-\u4DB5\u4E00-\u9FEA\uFA0E\uFA0F\uFA11\uFA13\uFA14\uFA1F\uFA21\uFA23\uFA24\uFA27-\uFA29]|[\uD840-\uD868\uD86A-\uD86C\uD86F-\uD872\uD874-\uD879][\uDC00-\uDFFF]|\uD869[\uDC00-\uDED6\uDF00-\uDFFF]|\uD86D[\uDC00-\uDF34\uDF40-\uDFFF]|\uD86E[\uDC00-\uDC1D\uDC20-\uDFFF]|\uD873[\uDC00-\uDEA1\uDEB0-\uDFFF]|\uD87A[\uDC00-\uDFE0])+$/
traverse.default(ast, {
StringLiteral(path) {
if (chineseReg.test(path.node.value)) {
let replaceExpression = intlCall({
id: `${id++}`,
dm: types.stringLiteral(path.node.value)
})
if (path.findParent(p => p.isJSXAttribute()) && !path.findParent(p => p.isJSXExpressionContainer())) {
replaceExpression = types.JSXExpressionContainer(replaceExpression);
}
path.replaceWith(replaceExpression);
path.skip();
}
},
JSXText(path) {
if (chineseReg.test(path.node.value)) {
let replaceExpression = intlCall({
id: `${id++}`,
dm: types.stringLiteral(path.node.value)
})
replaceExpression = types.JSXExpressionContainer(replaceExpression);
path.replaceWith(replaceExpression);
path.skip();
}
},
})
}
然后是字符串模板,这里处理是有些复杂的,一个字符串模板经过parse之后内容会分散在quasis和expressions中,quasis是字符串模板中被表达式分割的部分,expressions中是表达式列表。
我们想要字符串模板的每一部分提取出来保留原始表达式作为占位符
TemplateLiteral(path) {
const quasis = path.node.quasis;
const expressions = path.node.expressions;
let hasChinese = false
for (const index in quasis) {
// 遍历字符串模板的模板部分有无中文
if (chineseReg.test(quasis[index].value.raw)) {
hasChinese = true
break
}
}
if (hasChinese) {
let dm = quasis[0].value.raw
let params = types.objectExpression(
expressions.map(expression => types.objectProperty(
expression,
expression
))
)
for (let i = 0; i < expressions.length; i++) {
dm += `{${expressions[i].name}}` // 这里只考虑变量的情况,更多情况不展开
dm += quasis[i+1].value.raw
}
path.replaceWith(intlCallWithParam({
id: `${id++}`,
dm: types.StringLiteral(dm),
params
}))
}
path.skip();
}
最后我们将开始的jsx进行编译得到的结果如下
/*
* @Date: 2023-05-29 20:22:28
* @Author: 枫
* @LastEditors: 枫
* @description: description
* @LastEditTime: 2023-06-01 21:36:48
*/
import React, { useState } from 'react';
import Header from './Header';
export default function BillList() {
const [count, setCount] = useState(0);
const clickHandler = () => {
setCount(count + 1);
};
return <div>
<Header title={f({
id: 0,
dm: "\u8D26\u5355\u5217\u8868"
})} />
{count}
{f({
id: 1,
dm: "\u54C8{count}b"
}, {
count: count
})}
<button onClick={clickHandler}>{f({
id: 2,
dm: "\u67E5\u770B\u8D26\u5355"
})}</button>
</div>;
}
这里只是示例,并没有很完善,比如多次格式化会导致嵌套,这里需要我们进行判断;文件头需要导入国际化的模块,这里并没有导入;标准的Key应该根据文件路径进行拼接,这里我们简单的用递增索引来代替了;需要将提取的文案进行翻译并保存到本地文件等。
控制台报错高亮显示代码
这里就用到了code-frame这个包,我们平时开发用到的各种 lint 都是基于这个工具进行的代码报错提示。
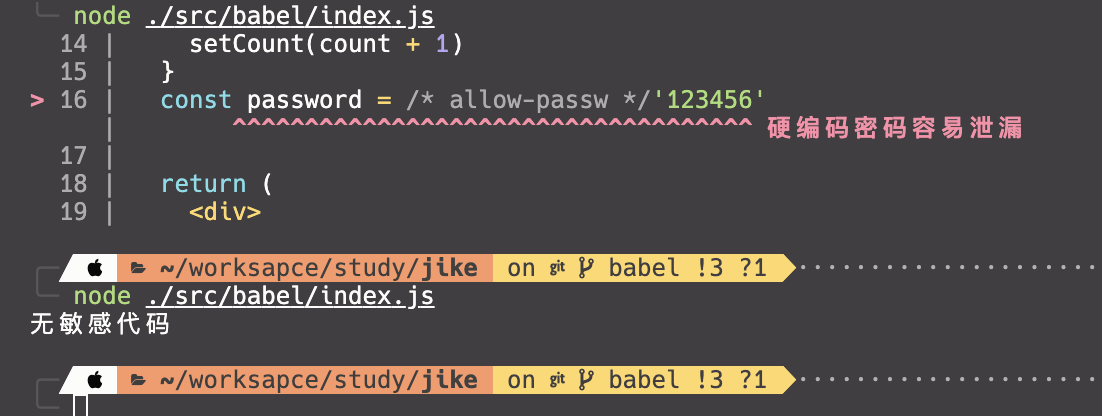
我们可以编写一个插件来检测代码中是否存在写死的硬编码的密码文本,防止泄漏机密,如果检测到有密码就在控制台进行报错,如果需要跳过可以通过魔法注释来进行跳过。
我们这里只考虑定义password变量,不考虑其他负载表达式,这里需要判断VariableDeclarator中node的id是否包含password关键字,比较简单
function checkPswd() {
const code = readFileSync(path.resolve(process.cwd(), './src/babel/index.tsx'), 'utf-8')
const ast = parseCode(code)
const result = check(ast)
if (result) {
const error = codeFrameColumns(code, result, {
highlightCode: true,
message: '硬编码密码容易泄漏'
});
console.log(error)
} else {
console.log('无敏感代码')
}
}
export function check(ast) {
let loc;
traverse.default(ast, {
VariableDeclarator(path) {
if (types.isIdentifier(path.node.id) &&
path.node.id.name.includes('password') &&
(types.isStringLiteral(path.node.init) ||
types.isTemplateElement(path.node.init))
) {
loc = path.node.loc
}
}
})
return loc;
}
此时执行一下代码可以看到效果
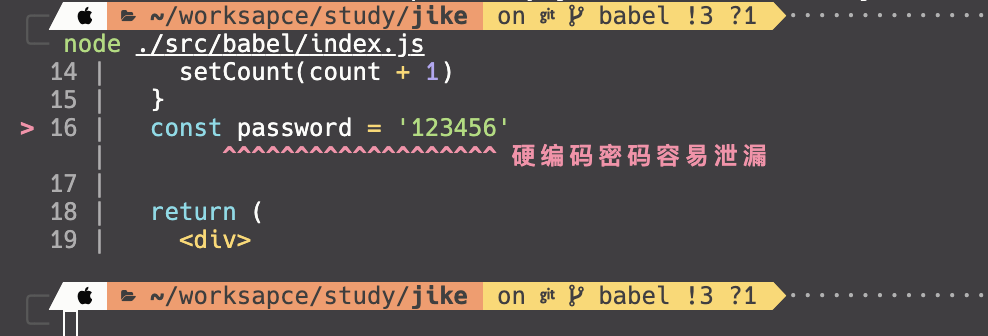
然后我们可以通过判断有无魔法注释来跳过,将判断逻辑进行完善
VariableDeclarator(path) {
if (!(path.node.init.leadingComments &&
path.node.init.leadingComments.some(
comment => comment.value.includes('allow-password')
)) &&
types.isIdentifier(path.node.id) &&
path.node.id.name.includes('password') &&
(types.isStringLiteral(path.node.init) ||
types.isTemplateElement(path.node.init))
) {
loc = path.node.loc
}
}
此时添加魔法注释/* allow-password */之后不再报错