



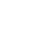



JS正则表达式
创建正则的两种方式:
- 创建字面量正则表达式,使用//包裹
let reg = /\w/
- 创建正则表达式对象,使用new RegExp()
let reg = new RegExp(/\w/)
选择符 |
“I” 左右两边匹配到一个就算是true
let str = '张三:010-1568413,李四:020-1586640'
let reg = /(010|020)\-\d{7,8}/
console.log(reg.test(str)); // true
转义
在字符串中\d和d是一样的
console.log('\d' === 'd') // true
在创建字面量的时候直接使用//创建,或者在字符串中转义
let str = '123.abc'
let reg = "\\d+\\.\\w+"
let reg2 = /\d+\.\w+/
console.log(str.match(reg));
console.log(str.match(reg2));
边界
以^开始,以$结束,可用于检测网址开头和文件后缀
^开始边界
let str = 'http:www.easyremember.cn'
let reg = /^https?:www\..+/
console.log(reg.test(str)); // true
$结束边界
let str = 'C://Users/All Users/abc.txt'
let str2 = 'C://Users/All Users/abc.log'
let reg = /\.txt$/
console.log(reg.test(str)); // true
console.log(reg.test(str2)); // false
元字符
\w:所有的字母、数字、下划线
\W:所有的非数字、字母、下划线
\d:所有的数字
\D:所有的非数字
\s:所有的空白字符,换行、空格等
\S:所有的非空白字符
.:除换行以外的任意字符
模式修饰符
i:不区分大小写
g:全局匹配
y:从lastIndex开始匹配
u:处理UTF-16编码字符
m:多行处理
s:单行处理,忽略换行符
原子表
| 原子表 | 说明 |
|---|---|
| [] | 只匹配其中的一个原子 |
| [^] | 只匹配”除了”其中字符的任意一个原子 |
| [0-9] | 匹配0-9任何一个数字 |
| [a-z] | 匹配小写a-z任何一个字母 |
| [A-Z] | 匹配大写A-Z任何一个字母 |
Tips:
\d == [0-9]
\D == [^0-9]
原子组
使用()包裹
引用分组:引用之前原子组匹配到的内容,\1\2……
let str = 'abc123.c123'
let reg = /([a-z]\d+)\.\1/g
console.log(str.match(reg)); // ["c123.123"]
分组别名
为不同分组命名,使用?<>命名,使用$<>引用
let str = 'abc123.c123'
let reg = /(?<init>[a-z]\d+)\.\1/g
// console.log(str.match(reg));
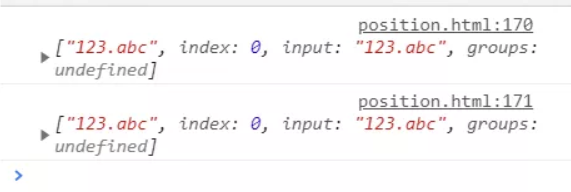
console.log(str.replace(reg, `<p>$<init></p>`));
重复
+:重复一次或多次
*:重复零次或多次
?:重复零次或一次
{n}:重复n次
{n,}:重复n次或更多次
{n,m}:重复n次到m次
let str = '1234'
let reg = /\d/
let reg2 = /\d+/let reg3 = /^\d{1,2}$/
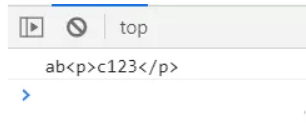
console.log(str.match(reg));
console.log(str.match(reg2));
console.log(reg3.test(str));
字符方法
search
返回要搜索内容的索引,没有返回-1
let str = 'abcdef'
console.log(str.search('ef'));// 4
console.log(str.search(/\w/)); // 0
console.log(str.search('efg')); // -1
match
使用字符串或者正则表达式匹配,返回匹配的内容,匹配不到返回null
let str = 'abcdef'console.log(str.match('ef')); // ef
console.log(str.match(/\w+/)); // abcdef
matchAll:
返回一个可迭代对象
let reg = /<(h[1-6])>[\s\S]+<\/\1>/g
let str = `<h1>前段小枫</h1>
<h2>blog.easyremember.cn</h2>`
for (let s of str.matchAll(reg)) {
console.log(s);
}

split:
使用字符分割字符串
let str = 'abc/def/123'
console.log(str.split('/'));
// ["abc","def","123"]
replace
替换字符为
let str = 'abc/def/123'
console.log(str.replace(/\W/g, '-'));
// abc-def-123
正则方法
test
检测字符串是否符合要求,返回值是一个布尔值
exec
不使用全局匹配与match相同,使用全局匹配会匹配完全部字符串,返回结果是一个可迭代对象
let reg = /<(h[1-6])>[\s\S]+<\/\1>/g
let str = `<h1>前段小枫</h1>
<h2>blog.easyremember.cn</h2>`
console.log(reg.exec(str));
console.log(reg.exec(str));

断言
?=exp
相当于if,但是是后置的例如
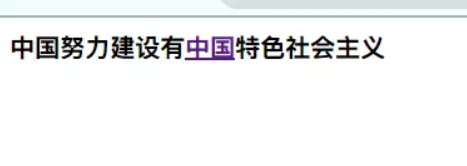
<main> 中国努力建设有中国特色社会主义</main>
<script type="text/javascript">
let reg = /中国(?=特色)/
let str = document.querySelector('main')
str.innerHTML = str.innerHTML.replace(reg, '<a href="">中国</a>')
</script>
?<=exp
前置断言
let reg = /(?<=有)中国/
let str = document.querySelector('main')
str.innerHTML = str.innerHTML.replace(reg, '<a href="">中国</a>')
效果跟前面的?=效果是一样的
?!exp
后面不能出现exp匹配到的内容
?<!exp
前面不能出现exp匹配到的内容



